
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. PROBLÉMATIQUE
🌪️ Et si ton infra tombait…
Tu gères des VMs, du PaaS, du stockage, peut-être des workloads critiques. Tout tourne bien.
Mais as-tu déjà imaginé ce qui se passe quand tout s’arrête sans prévenir ?
Une mise à jour réseau qui dégénère, un opérateur qui supprime une ressource par erreur, une région Azure qui devient indisponible…
Les causes sont multiples.
Et ce jour-là, tu n’auras pas le temps de chercher la doc. Ce qu’il te faut, c’est un plan clair, testé, maîtrisé.
🎯 C’est là qu’interviennent le PRA (Plan de Reprise d’Activité) et le PCA (Plan de Continuité d’Activité).
Ce ne sont pas juste des options qu’on active dans un portail Azure.
Ce sont des choix d’architecture, des scénarios à anticiper, et une orchestration à préparer à l’avance, bien avant que la panne ne survienne
3. FONDAMENTAUX (PRA vs PCA)
On entend souvent ces deux termes utilisés indifféremment, comme s’ils désignaient la même chose.
Mais en réalité, le PCA et le PRA répondent à deux besoins très différents
Le Plan de Continuité d’Activité (PCA)
Le PCA, c’est ce qui évite que ton service tombe.
C’est de la résilience intégrée à ton architecture : on anticipe, on redonde, on absorbe les chocs
🎯 Objectif : continuer à fonctionner malgré un incident.
Dans Azure, ça peut vouloir dire :
- Déployer en multi-zones pour survivre à la perte d’un datacenter
- Répartir la charge entre plusieurs régions avec Traffic Manager ou Front Door
- Utiliser un cluster PaaS en géo-réplication active (Azure SQL, Cosmos DB…)
📌 Le PCA, c’est proactif : tu prépares ton infra pour ne jamais t’arrêter.
Le Plan de Reprise d’Activité (PRA)
Le PRA, c’est ce qui entre en jeu quand tu n’as pas pu éviter la panne
🎯 Objectif : reprendre rapidement l’activité après un arrêt complet ou partiel
Là, on parle de :
- Restaurer une VM depuis une sauvegarde (via RSV)
- Basculement orchestré vers un site secondaire (via ASR)
- Rétablissement manuel ou semi-automatisé de services critiques
📌 Le PRA, c’est réactif : il te permet de revenir en ligne proprement, avec un impact minimal sur les données et les utilisateurs
RTO ? RPO ? SLA ? Il faut parler la même langue
Avant de dessiner des schémas ou de déployer quoi que ce soit, il faut s’accorder sur les objectifs métiers.
Le PRA/PCA ne commence ni avec ASR, ni avec une ligne Terraform.
Il commence avec un tableau blanc, et des questions simples :
- Combien de temps l’activité peut-elle être interrompue ?
- Combien de données peut-on se permettre de perdre ?
- Quelle est la disponibilité cible du service ?
- Quels engagements prend Azure sur les services utilisés ?
Recovery Time Objective (RTO)
⏱️ Combien de temps suis-je prêt à attendre pour que mon système redevienne opérationnel ?
Exemples :
- Site e-commerce → RTO 15 min (vente perdue = argent perdu)
- Intranet RH → RTO 4h (impact modéré, tolérance plus haute)
🎯 Le RTO détermine les outils qu’on va mobiliser :
👉 Orchestration automatique ? Redéploiement manuel ? Cluster actif/passif ?
Recovery Point Objective (RPO)
📉 Combien de données puis-je perdre sans que cela devienne critique ?
Exemples :
- Base de données client → RPO 5 min (toute perte est critique)
- Fichiers partagés d’archives → RPO 24h (peu d’écritures fréquentes)
🎯 Le RPO influence directement la fréquence de réplication ou de sauvegarde.
Service Level Agreement (SLA)
🔐 Engagement contractuel d’Azure sur la disponibilité d’un service.
| Service Azure | SLA Standard |
|---|---|
| Azure VM avec 1 instance | 99.9% |
| Azure VM dans un AS + 2 zones | 99.99% |
| Azure SQL avec geo-replica | 99.99% |
| Azure Storage RA-GRS | 99.99% lecture |
| Azure Front Door | 99.99% globalement |
| Azure Trafic Manager | 100% |
| ⚠️ Ces chiffres ne couvrent que la couche Azure. Ils ne garantissent pas que ton application respecte ce même niveau de dispo |
Service Level Objective (SLO)
🧭 L’objectif interne, que tu te fixes vis-à-vis des métiers.
Exemple :
- L’équipe Cloud vise 99.95% de dispo pour un portail client.
- L’équipe DevOps impose un RTO < 30 min pour toute app exposée.
🎯 Le SLO est plus exigeant que le SLA. Il est souvent contractualisé en interne avec les métiers.
| 🟢 Résumé : – Ton RTO guide la vitesse de reprise – Ton RPO définit la perte de données acceptable – Le SLA, c’est ce qu’Azure promet – Le SLO, c’est ce que toi tu dois garantir 👉 Et c’est en croisant les exigences métiers avec les limites techniques qu’on bâtit une vraie stratégie PRA/PCA. |
Outils Azure dans une stratégie PRA / PCA
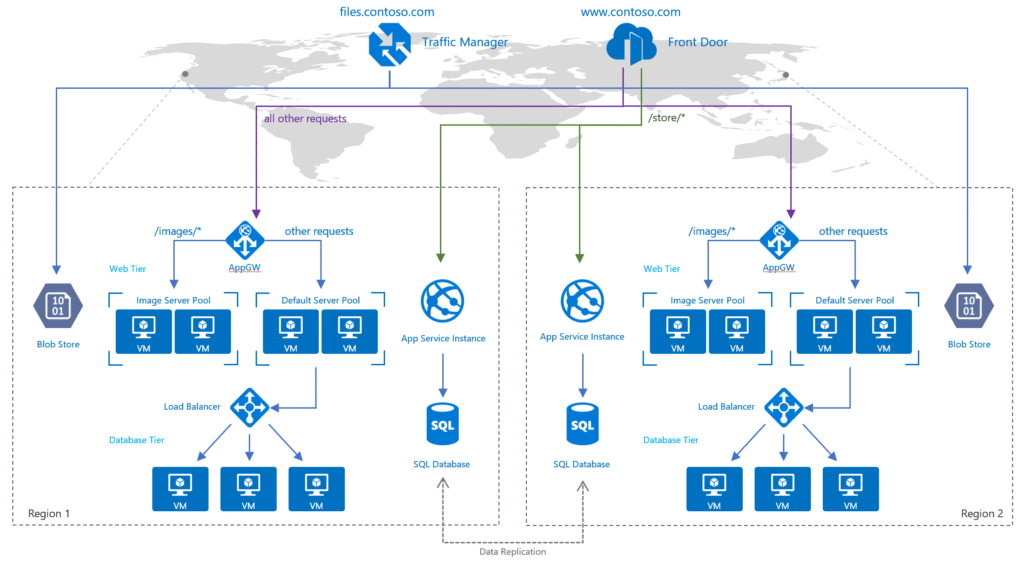
Azure fournit toutes les briques pour construire une stratégie de résilience solide.
Mais attention : c’est à toi de les assembler intelligemment, selon ton contexte, tes contraintes, et ton budget.
Voici les principaux outils à connaître et comment les utiliser dans une approche structurée PRA / PCA
Catégorie 1 : Sauvegarde & restauration
| Outil | Rôle principal | Détails |
|---|---|---|
| Recovery Services Vault (RSV) | Sauvegarde des VMs, fichiers, bases | Intégration native avec Azure VM, Azure SQL, SAP HANA, etc. |
| Azure Backup Center | Supervision centralisée | Vue globale multi-vaults, alertes, conformité |
| Snapshot managés | Restauration rapide de disques | Idéal pour les sauvegardes à chaud ou hors RSV |
| Azure File Share Backup | Protection des partages de fichiers | Compatible avec Azure Files (Standard/Premium) |
| ⚠️ Retenir : les sauvegardes protègent tes données, pas ton application dans son ensemble. |
Catégorie 2 : Réplication & failover
| Outil | Rôle principal | Détails |
|---|---|---|
| Azure Site Recovery (ASR) | Réplication des VM (Azure↔Azure ou OnPrem↔Azure) | Orchestration, test plan, failover et fallback |
| Azure SQL Geo-Replication | Continuité PaaS SQL | Active/Passive ou Failover Group automatique |
| Azure Storage GRS / RA-GRS | Redondance inter-région | Résilience sur les blobs, table, queues |
| Azure PostgreSQL / Cosmos DB DR | Réplication PaaS managée | Geo-redundant avec bascule contrôlée ou automatique |
| ⚠️ ASR est l’outil le plus complet pour IaaS, mais il ne couvre pas tout (ex : App Services, etc.). |
Catégorie 3 : Routage & supervision multi-région
| Outil | Rôle principal | Détails |
|---|---|---|
| Azure Front Door | Routage mondial avec failover automatique | Idéal pour apps web, supporte le health check |
| Azure Traffic Manager | DNS load balancing | Bascule conditionnelle basée sur la dispo régionale |
| Azure DNS | Gestion centralisée des zones DNS | Important pour basculer les endpoints rapidement |
| Application Insights / Log Analytics | Visibilité temps réel | Alerting + détection d’anomalies (down, latence, etc.) |
| ⚠️ Le routage, c’est le point faible de 80% des plans PRA non testés. |
Catégorie 4 : Orchestration & test
| Outil | Rôle principal | Détails |
|---|---|---|
| Azure Automation / Runbooks | Exécution de tâches répétables | Idéal pour exécuter un scénario de bascule custom |
| Logic Apps | Orchestration visuelle + intégration ITSM | Intégration facile avec ITSM, Slack, Teams, etc. |
| Azure Chaos Studio | Simulation d’incidents | Injection de pannes sur VM, réseau, etc. |
| Azure Blueprints / Bicep / Terraform | Redéploiement infra | En cas de DR total, tu dois savoir reconstruire rapidement |
| ⚠️ Un PRA sans test régulier = illusion de sécurité. La vraie maturité, c’est l’automatisation du test de reprise. |
Idées reçues et pièges fréquents
Un PRA/PCA mal pensé, c’est souvent un faux sentiment de sécurité.
Et ce n’est pas la technologie qui manque, c’est la connaissance des risques et le réalisme dans les choix.
Voici les erreurs les plus courantes qu’on voit en entreprise, même dans des architectures cloud avancées.
“Azure garantit la haute disponibilité, je suis tranquille”
Pas tout à fait. Azure te garantit la disponibilité de ses services, pas celle de ton application.
- Une région peut tomber (ex : incidents West Europe 2023).
- Un service peut être partiellement dégradé (ex : App Service plan bloqué).
- Un bug dans ton déploiement n’est pas couvert par le SLA Azure.
🎯 C’est à toi de concevoir une résilience applicative au-dessus des SLA Azure.
“On testera le failover en cas d’incident”
Erreur critique. Le test à froid, c’est trop tard.
- Les DNS ne basculent pas automatiquement.
- Le vault est peut-être incomplet.
- Le script de relance a été modifié et plus personne ne le connaît.
- La réplication ne couvrait pas tous les disques.
🎯 Un PRA/PCA non testé = un PRA/PCA inexistant.
“On veut 0 perte, 0 interruption, 0 impact… et 0 coût”
Ça n’existe pas.
Chaque seconde de dispo a un coût. Chaque RPO plus bas consomme plus de ressources.
🎯 Le bon équilibre, c’est celui où le risque métier est aligné avec le budget réel et la technologie maîtrisée
À retenir
- Un PRA/PCA, c’est d’abord une démarche métier avant d’être technique.
- Sauvegarde ≠ reprise. SLA Azure ≠ continuité applicative.
- Sans test, sans orchestration, et sans documentation claire, ton plan ne sert à rien.
PROCHAIN ARTICLE
Dans cette seconde partie, on entre dans le concret 💪 :
Sauvegardes, réplications, orchestration :
tout ce qu’il faut pour bâtir un PCA IaaS solide, sans illusions.
Au programme :
- Azure Backup / RSV : ce que ça protège… et ce que ça ne fait pas
- Azure Site Recovery : architecture, bascule régionale, pièges réels
- Comment structurer un plan de reprise avec des VM, du réseau, et des dépendances
- Pourquoi 90% des tests ASR échouent la première fois (et comment éviter ça)
🎯 Objectif : poser les fondations d’un plan PRA réaliste, adapté à ton infra, et surtout testable.



