
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
📋 Dans cet article
2. PROBLÉMATIQUE
Tu peux avoir une infra bien répliquée,
des runbooks testés jusqu’à l’usure,
et des scripts de bascule qui tournent comme une horloge…
Mais si, au moment critique :
• Personne ne sait quelles équipes doivent être relancées en priorité
• Aucune app n’est marquée comme vitale,
• Et on se demande qui donne le go pour la cellule de crise…
👉 Alors, tu n’as pas un PRA. Tu as juste une checklist technique
Un PRA, ce n’est pas seulement de l’infra, des scripts ou des backups. C’est d’abord du business : savoir ce qui compte vraiment, ce qui coûte cher à l’arrêt, et comment redémarrer vite quand ça plante. Dans le cloud, Azure assure le matos, mais c’est à toi de bâtir une archi qui protège tes apps critiques.
Et attention : une panne, c’est rarement tout qui s’écroule. Souvent, c’est un service ou une zone qui lâche
Ça commence dans un atelier, avec les métiers
autour d’un tableau blanc, à poser les bonnes questions :
- Qui impacte quoi ?
- Quel service coûte combien à l’arrêt ?
- Et qu’est-ce qu’on fait, dans quel ordre, quand tout plante ?
🎯 Ce deuxième article de la série PRA/PCA IaaS aborde les 50 % qu’on ne code pas :
- les arbitrages métier, les priorités d’accès, les scénarios réels
- et la coordination humaine qu’aucun script ne remplace
3. IDENTIFIER LES RÔLES CRITIQUES
Tu veux prioriser les bons accès le jour J ?
Commence par comprendre qui fait quoi
Un PRA efficace, ce n’est pas “tout rétablir le plus rapidement possible”
C’est redonner la main rapidement aux fonctions qui portent ton service métier.
Ta mission ici : cartographier les rôles qui :
- déclenchent des impacts financiers ou juridiques en cas de coupure prolongée
- gèrent la relation client ou la production en temps réel
- ont besoin d’un accès immédiat à l’application, même en mode dégradé
Exemples concrets :
- Dans une appli RH : l’équipe paie → ⚠️ délai légal
- Sur une plateforme logistique : l’équipe d’expédition → 💸 retards de livraison
- Dans un call center : l’outil de ticketing → 🔥 impact direct client
| 💡 Optimisation possible : Ne fais pas tout à la main. Utilise une CMDB (comme ServiceNow), une base Confluence, ou interconnecte les métadonnées de ton Cloud (tags Azure, labels Kubernetes…) pour documenter automatiquement les dépendances critiques. |
Schéma de criticité des apps :

4. TRAVAILLER AVEC LES MÉTIERS
Une bonne approche PRA, c’est collaboratif.
Il faut réunir les équipes techniques et les représentants métier pour :
- Identifier les dépendances critiques (base, proxy, ESB, stockage partagé…)
- Valider les priorités : qui doit revenir en premier, et pourquoi ?
- Recenser les contraintes d’accès (VPN, badge, IP filtrée, MFA…)
| ⚠️ Attention aux dépendances cloud : Une panne d’Azure Blob Storage peut bloquer une app si un service en dépend. Mappe ces liens dans tes ateliers IT/métiers |
Crée un fichier de travail partagé qui liste pour chaque application:
- Rôle ou service utilisateur
- Impact métier
- RTO cible
- Risques connus / limitations
- Actions à enclencher / contacts
➡️ Ce fichier devient ton référentiel de priorisation , centralisée (Confluence, Azure DevOps Wiki), validée par IT et métiers, pour guider tous tes scénarios
| 💡 Optimisation possible : Automatise le lien entre tes ressources cloud et les rôles métier via des outils comme Confluence ou une CMDB dynamique. Tu peux même enrichir chaque ligne avec les tags Azure (‘criticité=platine’, ‘RTO=2h’) directement liés aux services concernés. |
5. PAS DE REPRISE SANS PRIORITÉ CLAIRE
Quand la reprise s’enclenche, tout ne revient pas en même temps.
Les accès critiques doivent être disponibles dans les premières minutes
🔥 C’est là que se joue la différence entre un PRA théorique… et un vrai plan opérationnel.
Objectif :
👉 établir un plan de reprise lisible, priorisé, validé par les métiers ET par l’IT.
Trois leviers à croiser :
- Les rôles critiques → Ceux qui déclenchent un impact si on ne les relance pas vite
- Les accès vitaux → Applis, bases, VPN, qui doivent revenir avant tout
- Les ressources techniques → Ce qu’il faut restaurer, ouvrir ou sécuriser pour que ça reparte
Choisis ton niveau de résilience
- HA locale : Redondance dans une zone (cluster AKS) pour les apps Silver
- Multi-AZ : Actif/actif sur plusieurs zones (VM en Availability Set) pour Gold
- Multirégion : Réplication géo pour Platine/Diamant.
Adapte au RTO et au budget
Mode dégradé, ton joker
Si le SIRH tombe, bascule sur un fichier CSV. Tester ces plans B en simulation
Exemple de grille de priorisation :

6. GÉRER LA CRISE HORS CONNEXION
Tu peux avoir Teams, une cellule de crise bien rôdée, et un plan de conf call par service…
Mais si la connectivité tombe, et que tout s’écroule ?
Tu te retrouves à chercher un numéro sur SharePoint… inaccessible
✅ Prévois des canaux de secours :
- Messageries alternatives : Signal, WhatsApp, SMS natif
- Moyens physiques : Talkies-walkies pour les équipes on-prem
- Plan B : contacts critiques stockés hors ligne dans un PDF crypté sur clé USB ou laptop local
Et surtout, constitue un kit de crise hors ligne :
- 🟢 Runbook et Playbook PRA en version PDF (chiffré)
- 🟢 Contacts critiques imprimés ou exportés avec un QR code local
- 🟢 Procédures papier pour les scénarios majeurs
- 🟢 Fiches réflexes pour activer rapidement les bonnes personnes
Ce kit doit être stocké dans un endroit sûr… mais connu de tous les acteurs clés
🎯 Objectif : garantir la coordination, même en mode totalement déconnecté.
7. FORMALISER LES RESPONSABILITÉS ET LES RUNBOOKS
Un bon PRA
C’est une équipe prête, qui sait :
- 🟢 quoi faire
- 🟢 quand le faire
- 🟢 et surtout qui le fait
Et ça, ça ne s’improvise pas le jour J
Ce qu’il faut cadrer clairement :

Bonnes pratiques terrain :
- Liste des contacts / noms / numéros
- Support partagé : OneNote, Git markdown, SharePoint
- MAJ après chaque changement de rôle ou périmètre
8. ANTICIPER ET COORDONNER LES CRISES
Une crise n’est jamais prévisible, mais elle doit être gérée avec rapidité et précision. Un PRA efficace anticipe les scénarios, structure la réponse et forme les équipes à réagir sous pression.
Voici comment préparer et coordonner une crise.
Scénarios de crise
Chaque scénario doit être documenté avec des déclencheurs, impacts et actions.
Voici les principaux cas à anticiper :
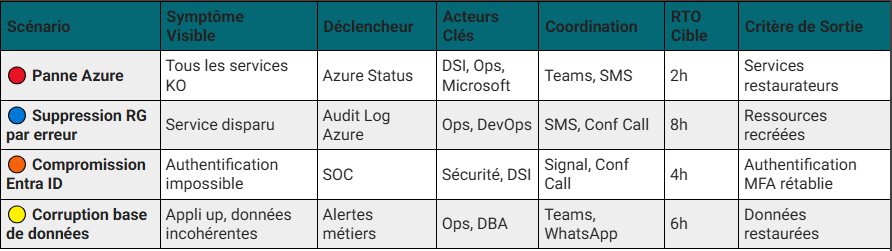
Pour chaque scénario :
- Mobiliser : Définir qui décide (DSI, Sécurité) et qui agit (Ops, Communication).
- Coordonner : Utiliser des canaux fiables (voir kit de crise hors ligne, section 7).
- Sortir : Valider la reprise avec des tests métiers.
Coordination en cellule de crise
La cellule de crise repose sur des rôles clairs et une communication fluide.
Posez-vous ces questions :
- Qui déclenche la crise ? (Ex. : DSI sur alerte Azure.)
- Qui décide du bascule ? (Ex. : Comité de crise.)
- Qui valide le retour à la normale ? (Ex. : Référent métier.)
- Qui informe les parties prenantes ? (Ex. : Communication.)
Fiche de coordination :

Bonnes pratiques :
- Documenter les escalades (N1 → N2 → N3).
- Créer un trombinoscope PRA (noms, photos, contacts) dans le kit de crise hors ligne.
- Stocker fiches et contacts dans un PDF crypté (voir section 7).
Simulations et amélioration continue
Un PRA se muscle par la pratique. Organisez :
- Simulations annuelles : Testez un scénario complet (ex. : panne Azure) avec IT et métiers.
- Mini-scénarios trimestriels : 1h de jeu de rôle avec un scénario surprise (ex. : ransomware).
- Tests expérimentaux : Simulez des pannes dans un bac à sable via Azure Chaos Studio.
| 🧪 Analyse post-simulation : – Dans ton post-mortem, note les écarts (ex. : RTO dépassé, canal HS) – Identifie les actions correctives (ex. : MAJ runbook, nouveau canal) |
Boucle d’amélioration (PDCA) :
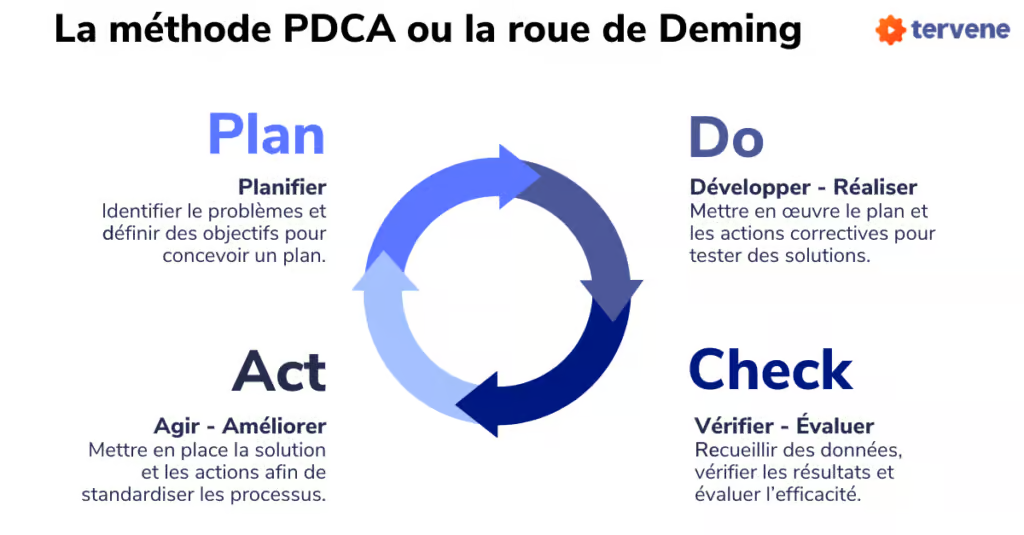
- Plan : Définir rôles, priorités, scénarios.
- Do : Simuler ou gérer un incident.
- Check : Analyser post-mortem (succès, échecs, actions ?).
- Act : Mettre à jour runbooks et playbook.
Optimisation terrain : Intégrez des canaux de secours (Signal, SMS, talkies-walkies) et testez-les lors des simulations. Ex. : Simulez une crise sans Teams pour vérifier le kit hors ligne.
PROCHAIN ARTICLE
Ton PRA est prêt ? Passe à l’action !
Azure Site Recovery (ASR) te permet de répliquer, basculer et reprotéger tes VMs avec une précision chirurgicale.
🔥 Pourquoi ASR ?
• Réplication continue : tes apps critiques (paie, CRM) restent synchronisées.
• Failover rapide : respecte tes RTO en cas de panne.
• Reprotection fluide : reprend le contrôle sans chaos.
💡 Comment faire ? Avec des scripts PowerShell pour :
• Configurer la réplication (ex. : VM multi-AZ).
• Exécuter un failover (ex. : panne Azure).
• Reprotéger tes ressources.
👉 À suivre : scripts éprouvés, bonnes pratiques, et pièges à éviter.
On met les mains dans le code !



