
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. PROBLÉMATIQUE
« Kubectl vraiment suffisant ? »
kubectl, c’est l’outil de base pour opérer un cluster Kubernetes.kubectl, c’est l’outil de base pour opérer un cluster Kubernetes.
Il est open source, maintenu par la CNCF, dispo partout, et c’est souvent la première interface qu’un Ops ou un architecte découvre.
Mais ce n’est pas un outil universel.
Tout le monde n’a pas une culture CLI.
Et certains rôles , data scientists, développeurs métiers, sécurité ne seront jamais à l’aise avec des lignes de commande ou des contextes changeants.
Et justement… c’est là que les erreurs commencent.
Dès qu’on gère plusieurs clusters, plusieurs environnements, plusieurs namespaces, on se retrouve vite avec :
“J’ai exécuté la commande sur le mauvais cluster…”
“J’ai déployé sur dev… en pensant être sur staging…”
“J’ai supprimé un namespace… mais pas le bon.”
Parce que kubectl garde ton contexte précédent.
Et à moins d’être ultra rigoureux, tu interagis souvent avec le mauvais environnement :
prod au lieu de dev, namespace monitoring au lieu de app, cluster Europe au lieu d’Asie.
À petite échelle, ça se rattrape.
Mais à partir de 10, 20, 100 clusters, avec plusieurs équipes et rôles croisés, ça devient un vrai problème d’exploitation.
Et kubectl, aussi puissant soit-il, ne suffit plus.
Trop d’outils, trop de choix
Quand on commence à outiller une équipe Ops autour d’AKS, la question arrive vite :
Quels outils choisir pour opérer mes clusters ?
Et là, l’écosystème CNCF ne nous aide pas beaucoup. Il y a beaucoup trop de solutions.
Chacune se réclame « cloud native ».
Chacune prétend être la meilleure.

On y trouve tout :
- des solutions historiques,
- des projets incubés ou récemment créés,
- des SaaS qui ne sont en fait que des wrappers sur des outils open source bien connus.
Et surtout : des solutions qui se superposent, voire se cannibalisent.
Heureusement, des standards émergents

Parmi ce bruit de fond technologique, certaines briques ont réussi à s’imposer.
| Solution | Rôle |
|---|---|
| Prometheus | Collecte de métriques, format standard, scrapping efficace |
| ElasticSearch | Moteur analytique performant pour les logs |
| Grafana | Visualisation centralisée (métriques, logs, traces) |
💡 Ces trois-là composent une stack cohérente : chacun couvre un pan de l’observabilité, et tout s’intègre nativement avec Kubernetes
Attention aux faux amis : le piège du “Open”
Tout ce qui commence par “Open” n’est pas forcément un gage de pérennité ou de pertinence.
Quelques exemples concrets :
- OpenMetrics : spin-off de Prometheus, censé améliorer le format… puis abandonné et réintégré dans Prometheus
- OpenTracing / OpenCensus : deux projets concurrents qui ont été supplantés par OpenTelemetry
Le problème n’est pas technique. Il est organisationnel et stratégique :
- 🔴 Ces projets peuvent changer de direction
- 🔴 Passer en modèle payant
- 🔴 Être abandonnés
- 🔴 Ou simplement, être mal documentés et peu utilisés
Choisir, c’est aussi penser au long terme
Opérer un cluster, ce n’est pas juste installer un dashboard.
C’est maintenir la solution dans le temps, savoir la mettre à jour, la comprendre, l’intégrer, et surtout recruter autour d’elle.
Et aujourd’hui, tu trouveras beaucoup plus facilement un ingénieur capable de déployer Prometheus avec Grafana, qu’un profil spécialisé sur un fork confidentiel ou un outil propriétaire en perte de vitesse.
STRATÉGIE : GARDER L’EXISTANT, MISER SUR LE CLOUD… OU REPRENDRE LA MAIN ?
Quand on parle d’observabilité, on pense souvent stack technique, mais la vraie question est ailleurs :
Est-ce que tu veux maintenir ta propre stack, ou déléguer une partie du run pour te concentrer sur tes workloads ?
C’est là que le choix stratégique se pose
Et il n’y a pas une bonne réponse universelle, mais trois approches réalistes, chacune avec ses bénéfices et ses contraintes.
1.Conserver : capitaliser sur ce qui fonctionne déjà
C’est l’option qu’on sous-estime souvent, et pourtant…
Si ton organisation utilise déjà une solution comme Zabbix, Datadog, Splunk, ou même une stack Grafana branchée à une base legacy (ou à Prometheus), il n’est pas obligatoire de tout jeter.
🌟 L’observabilité cloud-native, ce n’est pas forcément un outil.
C’est la capacité à exposer des signaux standards (logs, métriques, traces) depuis un cluster. Et ça, la plupart des outils savent déjà le faire.
✅ Garder sa stack, c’est :
- Zéro formation à prévoir
- Aucun changement dans les alertes ou dashboards
- Un ROI immédiat, car tout est déjà en place dans les équipes
- Et souvent… moins de friction dans l’ITSM ou les équipes sécurité
💬 Exemple typique : tu utilises déjà Grafana avec Zabbix ou FreeMonitoring sur des workloads legacy ? Tu peux très bien exposer les métriques Kubernetes via Prometheus et les faire ingérer par la même instance Grafana. Pas besoin de multiplier les plateformes.
📌 Ce scénario est appelé “Bring Your Own Monitoring” dans la documentation AKS
2.Investir : s’aligner sur l’écosystème Azure
Si tu veux aller vite, avoir une intégration native avec Azure, pas de stack à maintenir, pas d’alertmanager à configurer, alors l’écosystème Azure Monitor est une option très solide.
🔹 Tu as :
- Container Insights pour les logs et les métriques des pods/nœuds
- Azure Monitor workspace avec Prometheus en service managé (100% compatible PromQL)
- Azure Managed Grafana avec Single Sign-On Entra ID et team sync automatique
Tout est intégré, sécurisé, maintenu. Tu ne gères que tes dashboards.
👉 C’est le choix recommandé par Microsoft pour les équipes qui veulent se concentrer sur le métier, et non sur la maintenance d’une stack technique
3.Reprendre la main : full open source, full contrôle
Tu veux la main complète ? Tu veux savoir exactement comment sont collectées les métriques, où sont stockés les logs, et comment fonctionne l’alerting ?
Alors tu peux construire ta propre stack Prometheus + Grafana + Loki avec OpenTelemetry comme socle de collecte.
📦 Cette approche, appelée self-managed, est aujourd’hui celle choisie par des équipes exigeantes sur la souveraineté, le coût, ou la flexibilité.
Typiquement, tu déploies :
kube-prometheus-stack(Helm) pour Prometheus, AlertManager, node-exporter…loki-stackpour les logs applicatifsGrafanaOSS en interface unifiéeOpenTelemetry Collectorcomme agent de collecte
✅ Tu maîtrises tout.
⚠️ Tu gères tout.
🎯 Et tu dois prévoir une vraie stratégie de mise à jour, de haute disponibilité, d’alerting et de rétention
Pourquoi une seule stack est vitale
Un point que beaucoup découvrent (trop) tard :
Deux solutions de monitoring, c’est deux visions différentes du même problème.
Et dans Kubernetes, où tout est découplé (pods, services, bases, queues…), tu as besoin d’une seule vérité d’état, pas d’un puzzle incomplet.
Avoir Grafana ici, Datadog là, et Logs Analytics entre les deux ?
C’est le meilleur moyen de ne jamais comprendre un incident de bout en bout.
Tu hésites encore ? Pense en coût humain
Changer de stack, ce n’est pas que technique.
C’est aussi :
- Former tes équipes
- Réécrire tes dashboards
- Changer la façon dont tu alertes, ou escalades
- Briser l’automatisme de lecture des incidents
Et ça, c’est un coût
3. OUTILLAGE OPERATIONNEL
Dans le monde Kubernetes, on aime souvent dire que tout passe par des YAML et du CLI.
Mais au quotidien, ce n’est pas toujours la CLI qui sauve.
Entre besoins différents selon les rôles (Ops, Dev, Data, Sec), contraintes d’authentification, et ergonomie, on a besoin d’une boîte à outils cohérente, réaliste, et maintenable.
Et là encore, mieux vaut un outillage bien maîtrisé qu’une armée d’outils mal intégrés.
Kubectl 🟢
kubectl, c’est la CLI de référence pour interagir avec Kubernetes.
Open source, multi-plateforme, préinstallée dans Azure Cloud Shell, et facile à mettre à jour via :
az aks install-cli
Mais kubectl, c’est aussi :
- Un outil très extensible, via
krew, le gestionnaire officiel de plugins Kubernetes - Et donc une boîte à outils dans l’outil
👉 Quelques plugins incontournables à intégrer dès le départ :
| Plugin | Utilité |
|---|---|
ctx | Basculer rapidement entre clusters et namespaces |
rolesum | Visualiser les rôles RBAC appliqués à ton compte |
df-pv | Voir l’utilisation des volumes persistants |
deprecation | Identifier les objets obsolètes dans tes manifests |
Ces plugins te permettent d’anticiper les cassures lors des mises à jour K8s, où certaines APIs disparaissent
Visual Studio Code (VSCode) 🟢
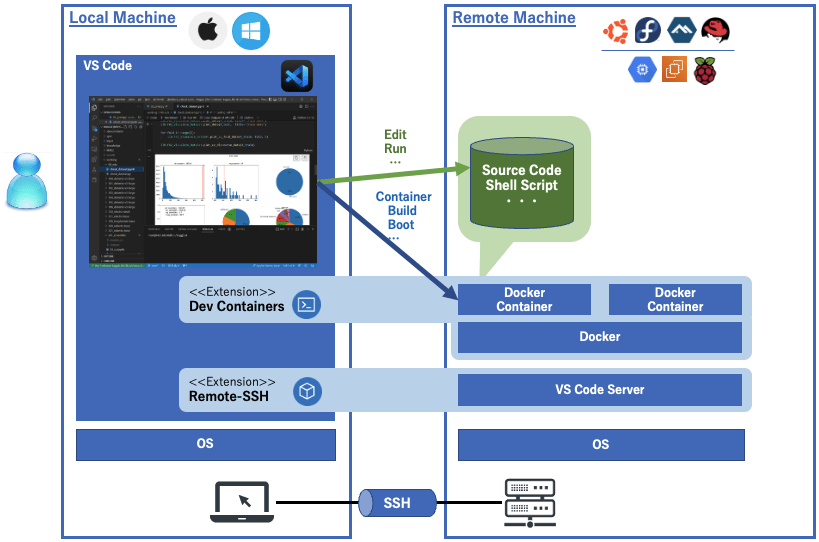
VSCode est devenu un véritable hub d’administration Kubernetes quand on y ajoute les bonnes extensions.
Fonctionnalités clés :
- DevContainers : environnement d’exécution Linux isolé par projet (via
.devcontainer) - WSL : support natif des devs sur Windows avec sous-système Linux
- Extensions AKS & Azure Pipelines : intégration directe avec Azure, déploiements, logs, context switch…
💬 Et dans les projets où tout le monde utilise des OS différents (Windows/Mac/Linux), les DevContainers garantissent une consistance locale et une vraie portabilité.
K9s 🟢
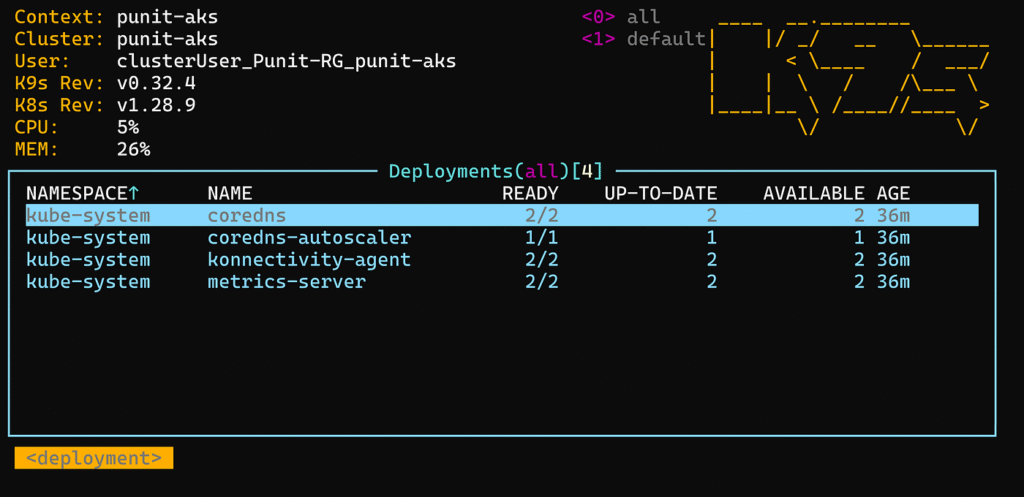
Si tu préfères le prompt à l’interface web, K9s est une perle.
- Interface TUI (terminal UI)
- Navigation intuitive dans les ressources (pods, deployments, logs, etc.)
- Entièrement open source
Tu peux presque tout faire avec, et c’est plus rapide que le portail Azure, surtout dans un environnement prod
Portail Azure 🟡
Le portail Azure est parfois tentant pour “juste jeter un œil”.
Mais il est très vite limité, surtout dès que :
- ton cluster est privé (VNet intégré)
- ou que tu veux aller plus loin qu’un simple
describe
⚠️ Tu n’as pas la main sur le kubectl, tu passes par l’API publique de Microsoft.
Donc pas d’accès aux clusters privés, et l’exécution de commandes (Run command) est très lente voire inutilisable en exploitation réelle.
En gros, utile pour de la lecture, des captures d’écran, ou de la formation… mais pas pour un run quotidien.
Lens / OpenLens 🟡
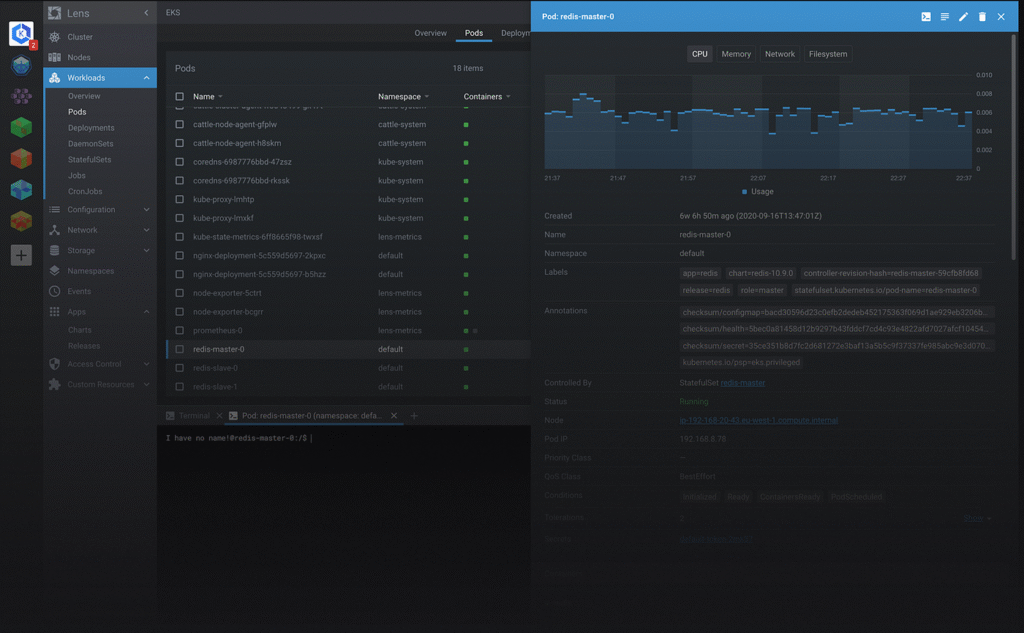
Lens, ou sa version libre OpenLens, c’est un kubectl avec interface graphique.
Ultra-pratique pour les profils moins à l’aise avec la ligne de commande.
Mais…
⚠️ L’authentification via Azure Entra ID n’est pas supportée nativement dans la version gratuite, ce qui pose problème dans un environnement sécurisé Azure.
Conclusion : utile en lab ou en dev, mais limité en production avec Azure AKS privé.
Popeye 🟢
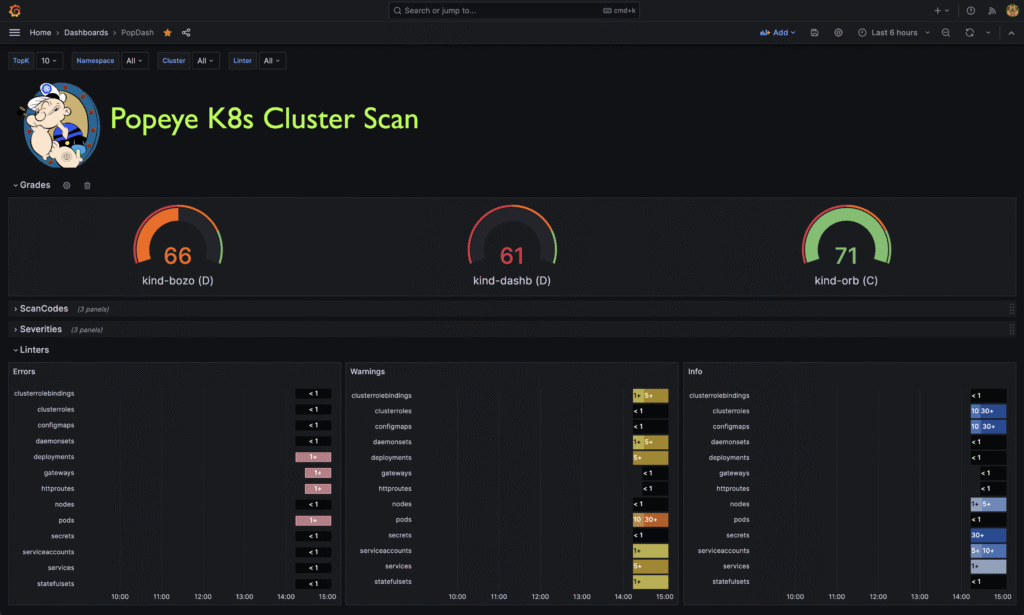
Un linter pour Kubernetes, qui détecte les mauvaises pratiques dans tes clusters.
- Analyse les ressources déployées : pods, services, secrets, etc.
- Repère les containers en crashloop, les ressources orphelines, les images non taggées…
- Résultats clairs, utilisable en CLI ou CI
💬 Parfait pour faire un état de santé rapide d’un cluster, ou avant une mise à jour majeure.
Stern 🟢
Pour lire les logs de plusieurs pods en simultané, avec filtrage par label/namespace.
- Idéal quand tu débugs un microservice réparti sur plusieurs pods
- S’utilise comme un
tail -fintelligent pour Kubernetes
💬 Une vraie valeur ajoutée en debug, surtout quand kubectl logs ne suffit plus.
Rancher 🟢

🔹 Rancher Desktop
Depuis que Docker Desktop est passé en modèle commercial (limité à 250 employés ou 10M€ CA), Rancher Desktop est l’alternative open source la plus fiable.
- Utilise Moby, le moteur container open source
- Compatible avec tous les workflows Docker
- Gratuit et maintenu par SUSE
🔹 Rancher Server
Rancher, c’est aussi une plateforme de gestion multi-cluster Kubernetes.
- Interface graphique complète
- Référencement de clusters existants (Azure, GCP, on-prem…)
- Provisioning de nouveaux clusters via une surcouche à
kubeadm - Authentification, RBAC, catalogues d’applications, etc.
Et surtout : une stack de supervision clé en main intégrée :
- Prometheus
- AlertManager
- Grafana
… le tout intégré dans une solution appelée Prometheus Federator
👉 C’est un vrai hub de supervision multi-cluster, sans avoir à tout reconstruire à la main
| ⚠️ Attention : Rancher Server est lui-même un cluster Kubernetes, avec tous les composants de gestion et de monitoring hébergés dedans ➡️ Si tu perds ce cluster sans stratégie de sauvegarde claire, tu perds l’accès : – à tes dashboards Grafana – à tes règles d’alerting Prometheus – à ta configuration de supervision |
PROCHAIN ARTICLE
Tu as maintenant une boîte à outils claire, pensée pour le terrain, et capable de sécuriser l’exploitation au quotidien.
Mais un bon outillage ne fait pas tout.
Il faut aussi comprendre ce qu’il se passe dans le cluster, savoir réagir vite, et surtout, garder le cap entre ce que tu déploies… et ce qui tourne réellement.
Dans la Partie 2, on aborde les sujets qui font la différence en production :
- 🟢L’observabilité, pour vraiment voir et corréler
- 🟢 Le GitOps, pour garder un environnement cohérent
- 🟢 Et le choix stratégique : stack managée dans Azure ou stack open source à la carte ?
Avec un seul objectif : garder la main, sans ajouter de complexité inutile
📎 Pour aller plus loin (docs Microsoft) :
- kubectl (doc officielle)
- Krew – Plugin Manager
- Liste des plugins utiles
- Dev Containers (VSCode)
- Extensions Kubernetes et Azure
- Site officiel K9s
- Rancher Desktop (alternative Docker)
- Rancher Server (multi-cluster)
- AKS avec Azure CLI
- Utiliser Cloud Shell
- Bring Your Own Monitoring
- Popeye
🙏 Remerciements
Cet article prolonge des échanges issus de plusieurs workshops conduits par Benoît Sautierre, dont la vision et l’animation ont largement nourri les réflexions présentées ici. Expert engagé et passionné, il a su créer un cadre de réflexion stimulant, pour lequel je lui adresse mes plus vifs remerciements.