
1. Intervenants
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. Problématiques
Compute AKS : Optimisation, Résilience et Maîtrise des coûts
| Élément | Risque sans contrôle | Objectifs de design |
|---|---|---|
| Surprovisionnement (waste) | Coûts élevés et inefficaces | Adapter la capacité réelle aux besoins métiers |
| Sous-provisionnement | Instabilités applicatives | Maintenir la performance et l’élasticité |
| Surcharge des Node Pools | SPOF, pods en erreur | Segmenter les workloads et répartir la charge |
| Mauvaise stratégie scaling | Temps de réponse trop long | Scalabilité intelligente avec autoscaler & KEDA |
| Manque de visibilité sur les coûts | Difficultés de pilotage | Mesure fine par pod, par pool, par workload |
| Multiplication des clusters | Complexité & facture élevée | Rationalisation des environnements AKS |
| Aucune politique de quota | Ressources accaparées | Équité entre équipes, bonne gouvernance |
| Stockage mal dimensionné | Saturation ou surcoût | Typage et sizing adaptés aux volumes utilisés |
💬 En résumé :
Le vrai défi n’est pas de “faire tourner AKS”, mais de le faire tourner durablement, efficacement, et sans surprises sur la facture
Cela passe par une gouvernance fine des compute nodes, une allocation maîtrisée, une anticipation des besoins et une supervision continue
3. Maîtriser du WASTE
Réduire les Coûts des Machines Virtuelles
Les nœuds AKS étant des machines virtuelles Azure classiques, maîtriser leur tarification est un levier puissant pour optimiser ta facture mensuelle.
Voici deux stratégies recommandées par Microsoft pour y parvenir
1.Reserved Instances
Tu réserves à l’avance une capacité de VM pour 1 ou 3 ans, ce qui permet d’obtenir un tarif largement réduit par rapport à une facturation à la demande
C’est une bonne option si tu es certain que ton cluster tournera en continu avec des besoins bien identifiés
Avantages :
- Jusqu’à 60-70% d’économie sur le coût des VM
- Idéal pour les charges prédictibles et longues durées (system node pool, backend métier, etc.).
Points de vigilance :
- Tu paies quoi qu’il arrive, même si la VM n’est pas utilisée
- Il faut bien anticiper les besoins réels avant de commander les capacité
- Changement de gabarit limité : les Reserved Instances offrent une flexibilité qui concerne uniquement les tailles au sein d’une même famille (par exemple, D2s_v3 vers D4s_v3), mais pas entre différentes familles ou régions
| 💡 Recommandation : Comme je le disais plus haut, je ne recommande pas de réserver dès le début. Commence simple, observe tes usages réels, et réserve uniquement quand tu es sûr de ton sizing et que tes workloads sont bien stabilisés |
2.Spot Instances
Les spot instances te permettent d’utiliser la capacité disponible temporaire d’Azure, à un prix très réduit.
Mais attention : Azure peut te retirer cette VM à tout moment si quelqu’un d’autre en a besoin. C’est donc une solution à réserver aux traitements non critiques.
Avantages :
- Très utile pour les jobs batch, les environnements dev/test, ou les workloads stateless.
- Tarifs imbattables, parfois jusqu’à 90% moins chers.
Points de vigilance :
- Pas de SLA garanti, donc à éviter en production
- Tu dois prévoir une stratégie de redémarrage/relancement automatique des pods
Bien choisir le nombre de clusters AKS
Un des premiers choix structurants quand tu déploies AKS, c’est :
Faut-il un cluster par application ? Un gros cluster partagé ? Un mix des deux ?
Scénario 1 —> Un cluster par application
Tu crées un cluster AKS dédié pour chaque app ou domaine fonctionnel.
Avantages :
- Tu peux optimiser les tailles de VM en fonction des besoins réels de l’app
- Séparation forte entre les environnements = plus simple pour les politiques de sécurité et de réseau
Inconvénients :
- Explosion du nombre de clusters = plus de gestion, plus d’overhead.
- Beaucoup de ressources gaspillées : chaque cluster a ses propres System Pods, Load Balancer, IP, etc.
- Ex : Dans certains cas observés chez de grands comptes, on peut atteindre 450 clusters gérés par seulement 2 personnes (cauchemar niveau ops ).
Scénario 2 —> Un cluster multi-applications avec overflow (ACI)
Tu mutualises les apps dans un même cluster, et en cas de surcharge, tu débordes temporairement via Azure Container Instances (ACI).
Avantages :
- Bonne mutualisation des ressources : tu fais plus avec moins.
- L’overflow via ACI peut absorber les pics de charge.
Inconvénients :
- L’intégration ACI est souvent jugée instable ou incomplète.
- Les workloads ACI peuvent avoir un comportement différent (perf, réseau).
- Peu de clients adoptent ce modèle de façon fluide à date.
Scénario 3 — Le “Giga Cluster”
Tu crées un seul cluster géant, qui héberge toutes tes apps
Avantages :
- Économie d’échelle maximale : un seul control plane, des ressources partagées, une seule gouvernance.
- Idéal pour centraliser la sécurité, les logs, les politiques globales.
Inconvénients :
- Maintenance complexe : Toutes les apps partagent le cycle de vie du cluster (Kubernetes version, maintenance, pannes)
- Risque accru : une mise à jour ratée ou un souci infra peut impacter plusieurs équipes.
- Les fenêtres de maintenance deviennent un casse-tête à gérer.
Conclusion : il faut trouver le bon équilibre
Il ne s’agit pas de choisir un modèle unique, mais plutôt de trouver un compromis intelligent
afin de minimiser les coûts inutiles et la complexité administrative tout en maximisant l’utilisation effective des ressources
| 💡 Ton choix de design doit aussi prendre en compte : – les contraintes de sécurité/réglementaires, – les besoins de montée en charge, – et le niveau d’autonomie des équipes. |
Résilience, Capacité & Stratégie d’Exploitation
Construire un cluster AKS ne se limite pas à le faire fonctionner. Il est essentiel de penser en termes de résilience, de capacité excédentaire, de maintenance, de visibilité des coûts et surtout d’allocation intelligente des ressources
Résilience & Capacité Excédentaire
Un cluster AKS doit être conçu pour résister aux pannes et assurer une disponibilité continue.
✅ Recommandations clés
- Minimum de 3 nœuds par pool de nœuds pour garantir la redondance, conformément aux recommandations de Microsoft
- Dimensionnement supérieur à 100 % des besoins actuels pour permettre aux nœuds restants de supporter la charge en cas de défaillance d’un nœud.
Objectif : Si un node échoue, les deux nodes restants doivent pouvoir supporter l’ensemble des workloads jusqu’à la reprovision
Isolation & Sécurité Inter-Workloads
Lorsque plusieurs équipes ou applications partagent un cluster, il est crucial d’éviter les interférences et de garantir la sécurité.
✅ Recommandations clés
- Isoler par namespace et appliquer des contrôles RBAC précis.
- Implémenter des NetworkPolicies pour restreindre la communication entre pods.
- Utiliser des taints et tolerations pour contrôler le placement des pods sur les nœuds.
Objectif : Cloisonner proprement les workloads, éviter les interférences entre équipes et réduire la surface d’attaque.
Maintenance & Stratégies de Mise à Jour
Gérer un cluster implique également de gérer son cycle de vie, notamment les mises à jour de Kubernetes qui peuvent être disruptives.
✅ Recommandations clés
- Stratégie Blue/Green : Créer un nouveau cluster avec la nouvelle version, tester, puis basculer.
- Mise à jour progressive par pool de nœuds : Mettre à jour un pool secondaire, observer le comportement, puis basculer les workloads progressivement.
Objectif :
- Eviter les upgrades massif sans plan de rollback testé , le mieux c’est les approches progressives (Blue/Green, etc.)
- Minimiser les interruptions et garantir la continuité des services.
Organisation & Gestion des Environnements
Multiplier les clusters peut sembler tentant, mais cela augmente la complexité administrative et les coûts.
✅ Recommandations clés
- Un cluster par environnement métier ou domaine, pour équilibrer isolation et efficacité opérationnelle
Objectif : Moins de clusters, mieux c’est pour réduire le « waste » et simplifier la gestion globale des ressources et de la facturation.

Visibilité des Coûts & Allocation des Ressources
AKS ne donne pas de coût “par pod” directement.
Et comme les pods peuvent vivre quelques secondes comme plusieurs semaines, c’est très difficile d’avoir une lecture fine de la conso réelle.
Chaque pod consomme différemment : CPU, mémoire, bande passante — ça varie d’une app à l’autre, et d’une minute à l’autre.
✅ Actions à entreprendre :
- Taguer les workloads pour les rattacher à une application métier.
- Suivre les consommations avec des outils comme OpenCost ou Azure Cost Analysis.
- Identifier les coûts fantômes : ressources inutilisées, idle, oubliées.
Objectif : Optimiser l’utilisation des ressources et éviter les surcoûts.
Stratégie d’Allocation : Guaranteed vs Burstable
AKS te permet de choisir la stratégie de consommation des ressources par pod :
| Type d’allocation | Description | Exemple de workload |
|---|---|---|
Guaranteed | Ressources garanties pour les workloads critiques | App critique (paiement, API Gateway) |
Burstable (default) | Peut consommer au-delà des requests si le nœud le permet | App classique |
BestEffort | Aucune garantie, placé sur ce qui reste | Script d’import, CI/CD, job éphémère |
Objectif : Optimiser l’utilisation des ressources, éviter les surcoûts en attribuant des workloads sur des nodes adaptés (ex. nodes GPU réservés pour workloads gourmands).

Limiter le waste avec LimitRange & ResourceQuota
Limit Range
Le LimitRange permet de fixer des bornes minimales et maximales sur les ressources consommées par chaque conteneur, dans un Namespace donné.
Tu peux définir :
- Spécifie les valeurs minimum (
min) et maximum (max) du CPU et RAM - un default pour les pods qui n’ont rien spécifié,
- Permet d’assurer un ratio équilibré entre les demandes (requests) et les limites (limits) des ressources
- et même des valeurs par défaut pour les PersistentVolumeClaims.
apiVersion: v1
kind: LimitRange
metadata:
name: resource-limits
namespace: my-namespace
spec:
limits:
- type: Container
min:
cpu: "100m"
memory: "128Mi"
max:
cpu: "1"
memory: "512Mi"
default:
cpu: "500m"
memory: "256Mi"
defaultRequest:
cpu: "200m"
memory: "256Mi"
Resource Quota
Contrainte globale au niveau du Namespace : :
- Limite la consommation agrégée de ressources (CPU, RAM, stockage, etc.) pour l’ensemble des objets du Namespace.
- S’applique à la fois aux demandes (requests) et aux limites (limits).
- Peut être étendu à d’autres types d’objets Kubernetes (ex. nombre de PersistentVolumeClaims).
Exemple de YAML – ResourceQuota :
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: my-namespace
spec:
hard:
requests.cpu: "4"
requests.memory: "8Gi"
limits.cpu: "8"
limits.memory: "16Gi"
persistentvolumeclaims: "10"
storage: "100Gi"
Ces mécanismes vous aident à :
- Limiter le waste en empêchant une consommation excessive ou non contrôlée de ressources.
- Assurer une répartition équitable des ressources entre les applications dans un Namespace.
- Garantir la bonne allocation des ressources en imposant des contraintes strictes dès le déploiement.
LimitRange = limite à l’échelle du podResourceQuota = quota global du namespace |
4.Outils pour maîtriser le waste
OpenCost
OpenCost, c’est un projet open source soutenu par la CNCF, conçu pour analyser les coûts d’un cluster Kubernetes, peu importe où il tourne.
Pourquoi c’est utile :
- Multi-cloud natif : fonctionne sur Azure, AWS, GCP, On-Premise, sans modification.
- Multi-cluster : tu peux centraliser les données de plusieurs clusters.
- Compatible avec Prometheus : facile à intégrer dans un dashboard Grafana ou Lens.
Détail des coûts fournis :
- Idle charges : Ressources allouées mais inutilisées (💸 = perte sèche)
- Service charges : Coûts des System Pods (CoreDNS, metrics-server…)
- System charges : Coûts obligatoires (réseau, load balancers, etc.)
- Unallocated charges : Ressources non attribuées à un workload précis (gros signal d’alerte ⚠️)
Plugins & intégration :
De nombreux plugins et exporters sont dispos pour intégrer OpenCost à vos outils de dashboarding (Grafana, Lens, etc.)
AKS Cost Analysis Add-on
Pour ceux qui préfèrent une intégration native dans Azure, Microsoft propose un add-on AKS directement basé sur OpenCost.
Avantages :
- Pas besoin de déployer quoi que ce soit manuellement
- Données de coûts visibles depuis le portail Azure ou via API
- Même logique de calcul qu’OpenCost
Coûts visibles :
- Idle charges
- Service charges
- System charges
- Unallocated charges
Limitations :
- Disponible uniquement avec les AKS Standard et Premium
- ❌ Pas compatible avec les clusters AKS en version gratuite
- Pas de support pour les plugins OpenCost → personnalisation très limitée

| Outil | Cas d’usage idéal | Flexibilité | Visibilité multi-cloud |
|---|---|---|---|
| OpenCost | Clusters multi-cloud, besoin de détail | ⭐⭐⭐⭐ | ✅ |
| AKS Add-On | Intégré, rapide à mettre en place | ⭐⭐ | ❌ Azure only |
| L’idéal : commencer avec l’add-on si tu es full Azure, puis passer à OpenCost dès que tu veux croiser avec d’autres clusters ou personnaliser tes analyses |
9.Design storage
Le stockage dans AKS, c’est souvent un sujet qu’on sous-estime… jusqu’à ce que les déploiements échouent parce que les disques sont pleins, ou que les performances chutent à cause de mauvais choix d’IOPS.
Voyons comment bien poser l’architecture storage côté cluster
OS Disk — Choix du disque pour les nœuds
Chaque nœud du cluster AKS possède un disque OS. Ce disque ne stocke pas que le système, il sert aussi à mettre en cache les images de conteneurs téléchargées. Un point critique pour la rapidité des déploiements.
Ce qu’il faut savoir :
- La taille et le type du disque OS dépendent de la taille de la VM.
- Les performances (IOPS, débit) sont directement liées à cette configuration.
- Si le cache se remplit (images Docker trop lourdes), les pods échouent au démarrage.
Recommandations :
- Pour le System Node Pool, reste sur du Premium SSD P10 (128 Go). Bon équilibre entre coût et performance.
- Évite les images container trop lourdes pour ne pas saturer le cache.
- Sur certaines séries (ex. Dsv3+), le caching disk est séparé de l’OS disk. Donc c’est plutôt le Local SSD (cache) qui sature pas le OS disk directement
- En environnement de développement ou Sandbox, pense aux disques éphémères : plus rapides, moins chers, et supprimés quand la VM s’éteint.
Tableau indicatif:
| VM (vCPU) | OS Disk par défaut | IOPS provisionnés | Débit (MBps) |
|---|---|---|---|
| 1 à 7 | P10 – 128 Go | 500 | 100 |
| 8 à 15 | P15 – 256 Go | 1 100 | 125 |
| 16 à 63 | P20 – 512 Go | 2 300 | 150 |
| 64+ | P30 – 1024 Go | 5 000 | 200 |
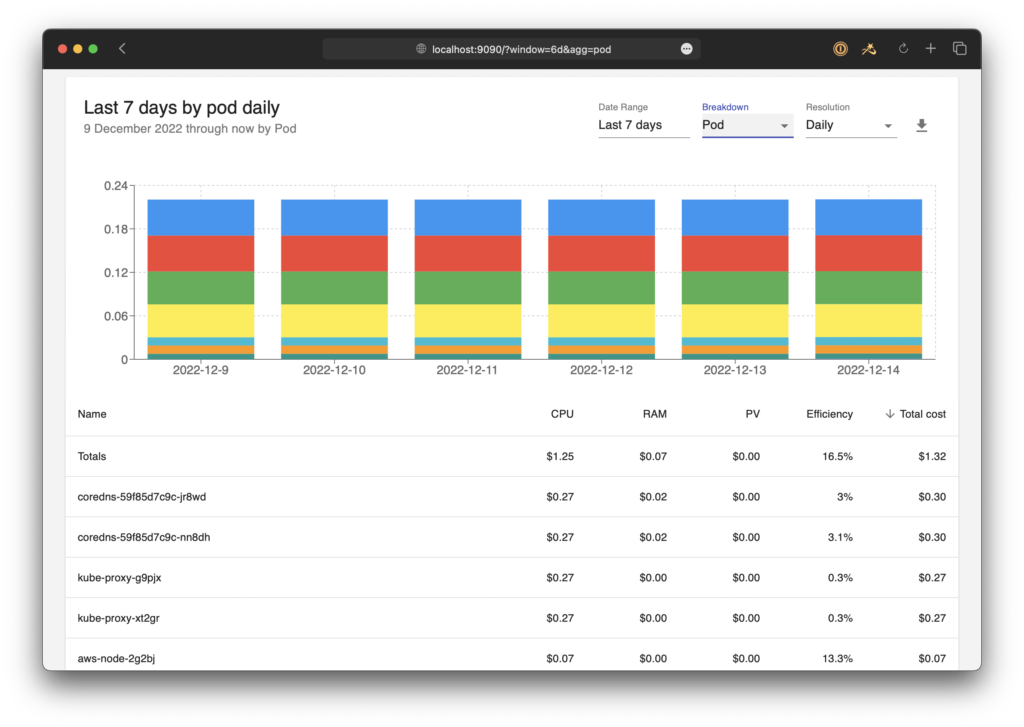
OS Disk Encryption — Sécurité des disques
Tous les disques sont chiffrés par défaut dans AKS
Détails techniques :
- Chiffrement automatique via des clés gérées par Microsoft (Managed Keys).
- Possibilité d’utiliser Disk Encryption Sets pour gérer les clés via Azure Key Vault
- Le chiffrement repose sur le CSI Azure Disk Driver.
Avantage :
- permet à l’équipe sécurité (ou au CISO) de gérer la rotation des clés et leur cycle de vie.
Volumes pour les workloads
Côté applicatif, les pods utilisent des volumes montés dynamiquement. Le provisioning peut être :
- Statique
L’admin crée les volumes à la main avec un StorageClass dédié.
- Dynamique (recommandé)
AKS provisionne automatiquement les volumes selon les PersistentVolumeClaim
Reclaim Policy — Que faire des volumes supprimés ?
Retain(souvent par défaut) : conserve les données même après suppression du PVC.Delete: supprime automatiquement le volume.Recycle: obsolète et à éviter.
Modes d’accès aux volumes
| Mode | Description |
|---|---|
ReadWriteOnce | Un seul pod peut écrire (le plus courant) |
ReadOnlyMany | Plusieurs pods lisent en parallèle |
ReadWriteMany | Plusieurs pods peuvent lire et écrire |
ReadWriteOncePod | Un pod unique accède au volume (nouveauté AKS ≥ 1.25) |
Types de stockage disponibles dans AKS
| Type de stockage | Quand l’utiliser ? |
|---|---|
| Azure Disk Premium SSD | Pour les applications critiques, besoin de faible latence |
| Azure Disk Standard SSD | Usage général, bon rapport coût/perf |
| Azure Disk Standard HDD | Très économique, mais lent (éviter si possible) |
| Azure Files (Standard/Premium) | Partage de fichiers entre plusieurs pods |
| Azure Ultra Disk | Workloads extrêmes (rarement nécessaire) => latence <1ms, IOPS très élevés |
| ⚠️ Attention : Ultra Disk n’est pas disponible dans toutes les régions, et pas compatible avec toute les tailles de VM. |
5.Hypothèses de calcul
Avant de concevoir une architecture AKS robuste, évolutive et optimisée, il est indispensable — en tant qu’architecte Azure — de poser les bonnes hypothèses dès le départ. Cette étape de cadrage permet de :
- 🟢Dimensionner correctement les ressources,
- 🟢Anticiper les points de friction (réseau, quota, gouvernance),
- 🟢Et surtout, éviter les redéploiements douloureux une fois en production.
Infrastructure
1.Nombre de clusters
👉 Voir la section « Bien choisir le nombre de clusters AKS » pour le détail des trois scénarios possibles :
Clusters par application, cluster partagé multi-apps, ou modèle hybride.
Ce choix a un impact immédiat sur :
- La charge opérationnelle
- Le coût global (multiplication des System Pods, Load Balancers, IPs…)
- La gouvernance réseau, la sécurité, et les rôles RBAC
2.Conseil d’architecte
Ne pense pas uniquement en coût ou en scalabilité. Intègre dans ton raisonnement :
- les exigences réglementaires,
- les enjeux de souveraineté,
- le niveau d’autonomie des équipes,
- et le modèle opérationnel cible
3.Zones géographiques
Tu dois prévoir où tes clusters vont tourner :
- Dans une ou plusieurs régions Azure (ex. France Central, West Europe, North Europe)
- En mode hybride Azure + On-Premise si besoin de latence faible ou souveraineté des données
Design de cluster
1.Nombre de node pools
Un cluster AKS monolithique, avec un seul node pool, est rarement une bonne idée. Il faut au minimum :
- 1 System Node Pool (pods système : CoreDNS, kube-proxy…)
- 1+ User Node Pools (applications, jobs, batch, ML…)
💡 Tu peux ajouter des pools spécialisés selon les cas d’usage :
- Pools GPU
- Pools Windows
- Pools à disques éphémères
- Pools Spot Instances
2.Type de scaling
Manual scale : recommandé au démarrage, quand la charge applicative est encore inconnue.
Cela permet de garder le contrôle.
Autoscaling :
- Cluster Autoscaler : ajuste le nombre de nœuds selon la pression des pods
- HPA (Horizontal Pod Autoscaler) : ajuste le nombre de pods
- KEDA : scale selon des événements externes (ex. files d’attente)
| 🎯 Bon réflexe : Commencer simple → observer → adapter. Ne pas configurer l’autoscaling sans visibilité sur les besoins réels. |
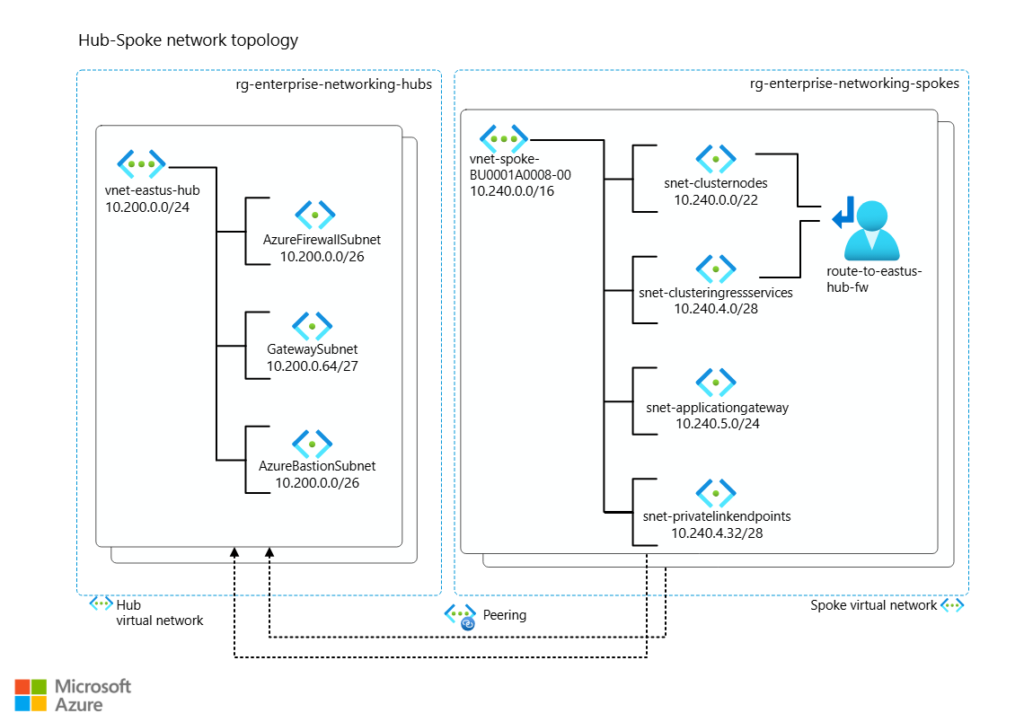
3.Capacité IP
Souvent oubliée… et bloquante.
- Réserve une plage CIDR suffisamment large dès la création du cluster (ex : /22 ou /23).
- Sépare bien les subnets (System, User, Services, LoadBalancers…).
- Si tu es en Azure CNI, fais attention aux quotas de pods par nœud.
Côté applicatif
1.Workloads à embarquer
- Applications, microservices, agents techniques, jobs CI/CD
- Classification par criticité (ex. SLA, disponibilité, backup, sécurité)
2.Nombre de pods
À estimer en incluant :
- Réplicas pour la haute disponibilité
- DaemonSets (ex. agents de monitoring ou sécurité)
- Sidecars (logging, proxy…)
- Jobs/Pipelines Kubernetes
Requests & Limits
Pour chaque pod, définis :
- Des requests (CPU/RAM garantis)
- Des limits (CPU/RAM maximums autorisés)
| Objectif : éviter les OOMKills, stabiliser le scheduler, et garantir la QoS sur chaque node |
3.Besoins en stockage
À évaluer par workload :
- Type de volume : Azure Disk, Azure Files, Ephemeral
- Mode d’accès : ReadWriteOnce, ReadWriteMany, etc.
- Capacité estimée (en GiB)
- Performance attendue (IOPS, Débit)
4.Scalabilité attendue
- Horizontal Scaling : plus de pods (HPA, KEDA)
- Vertical Scaling : plus de CPU/RAM (VPA)
- Event-driven Scaling : traitement par lot ou par trigger externe (ex. Azure Queue)
PROCHAIN ARTICLE
👉 Dans la prochaine et dernière partie de cette série AKS, on entre dans un sujet crucial : la sécurité.
Car un cluster bien dimensionné, c’est bien… mais un cluster sécurisé de bout en bout, c’est indispensable
Au programme :
- Sécurisation de la chaîne de build
- Azure Container Registry (ACR) et bonnes pratiques de registre
- Sécurité des workloads applicatifs
- Renforcement natif de Kubernetes : admission controllers, RBAC, NetworkPolicies
- Mise en place de politiques de conformité (OPA/Gatekeeper, Azure Policy pour AKS)
- Et bien plus encore…
📎 Pour aller plus loin (docs Microsoft) :
- Réservations Azure pour les Machines Virtuelles (Reserved Instances)
- Machines Virtuelles Spot Azure
- Analyse des Coûts dans AKS avec OpenCost
- Autoscaler de Cluster AKS
- Kubernetes Event-driven Autoscaling (KEDA)
- Meilleures Pratiques pour la Résilience dans AKS
- Utilisation de LimitRange et ResourceQuota dans Kubernetes
- Gestion des Ressources avec Azure Policy
- Concepts de Stockage dans AKS
- Pilotes CSI pour le Stockage dans AKS
- Sécurité de Base dans AKS
- Meilleures Pratiques pour la Sécurité des Clusters AKS
- OpenCost pour Kubernetes
- Analyse des Coûts AKS avec l’Add-on Azure
- Architecture de Référence pour AKS
- Meilleures Pratiques pour la Gestion des Pools de Nœuds
🙏 Remerciements
Cet article prolonge des échanges issus de plusieurs workshops conduits par Benoît Sautierre, dont la vision et l’animation ont largement nourri les réflexions présentées ici. Je lui adresse mes plus vifs remerciements