
1. Intervenants
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. Problématiques
Architecture AKS : Séparation des responsabilités
| Élément | Control Plane | Worker Plane |
|---|---|---|
| Responsabilité | 100% géré par Azure | Géré par le client (VMSS dans un Resource Group) |
| Visibilité | Caché | Visible et administrable |
| Composants | API Server, Scheduler, etc | Nodes qui exécutent les Pods |
| Facturation | Gratuit (Standard) / Payant ( Premium) | Payant (VMs, disques, LB, IP, trafic, monitoring, etc.) |
| SLA | 99.95% avec AKS Premium | Dépend du design (AZs, résilience des nodes) |
Enjeux de facturation côté Worker Plane
On ne paie pas le cluster AKS directement, mais tout ce qui tourne autour : « compute, stockage, réseau, monitoring… » :
- VMs dans les Node Pools : coût à l’heure, selon la taille de VM (ex: Standard_D4s_v3) et le mode (à la demande, reserved, spot)
- Disques : OS + données (Standard, Premium, Ephemeral).
- Load Balancers & IP publiques : un ou plusieurs par cluster selon l’exposition.
- Trafic réseau sortant : souvent oublié, mais impactant.
- Stockage applicatif : Azure Files, Azure Disks, persistent volumes.
- Fonctionnalités managées : monitoring, sauvegardes, logs…
💬 Bref : ce n’est pas “le cluster AKS” qui coûte cher, c’est ce qu’on en fait
Considérations techniques pour l’architecture Compute
Node Pools :
- Organisés en System Node Pools (composants systemes) et User Node Pools (workloads applicatifs).
- Plusieurs node pools = adaptation fine des tailles et des types de VMs aux workloads.
Ressources réservées par Kubernetes :
- Chaque node garde une part de CPU/mémoire pour ses propres composants (kubelet, CNI, etc.), ce qui réduit la capacité réelle disponible pour les pods
Hétérogénéité des workloads :
- Les workloads modernes ont des profils variés (CPU/mémoire, durée de vie, tolérance aux pannes).
- Nécessité d’un dimensionnement fin et évolutif, qui prend en compte :
- Le type de workload,
- Les besoins de scalabilité,
- Les exigences de sécurité.
3. Type de compute spécifiques
Dans la majorité des cas, déployer un cluster AKS avec des VM standards suffit largement.
Mais parfois, on a besoin d’aller plus loin : mieux isoler les workloads, exécuter du code ultra-sensible, ou simplement répondre à des contraintes réglementaires un peu costaudes.
Et là, Azure propose deux options intéressantes côté compute :
👉 les conteneurs isolés (sandboxed) et le Confidential Computing.
Kernel Isolation avec Sandboxed Containers
- Pourquoi ça existe ?
Normalement, Kubernetes isole les pods au niveau du runtime et du namespace, ce qui suffit dans 90% des cas.
Mais si tu gères une plateforme multi-client, un environnement sensible, ou que tu exécutes du code utilisateur « non maîtrisé », tu veux un niveau d’isolation plus poussé
C’est là qu’interviennent les conteneurs isolés au niveau noyau, aussi appelés sandboxed containers.
- Comment ça marche ?
On s’appuie sur Kata Containers, une techno qui permet de faire tourner chaque pod dans une micro-VM dédiée
✅ Ce que ça apporte
- Une vraie séparation entre les workloads : impossible pour un pod d’agir sur l’environnement d’un autre.
- Beaucoup plus robuste face à certaines attaques (container escape, side-channel, vulnérabilité noyau, etc.).
- Une vraie solution pour des plateformes SaaS qui hébergent du code client.
⚠️ Les limites
- Forcément, ça consomme un peu plus : latence au démarrage, overhead CPU, etc.
- Certaines fonctionnalités Kubernetes ne sont pas compatibles (ex : partage de volume entre pods, accès direct à certains devices).
- Pas compatible avec tous les plugins réseau
- Actuellement , Ce type de pool fonctionnent uniquement avec Azure Linux
- Et les images GPU ne sont pas compatibles
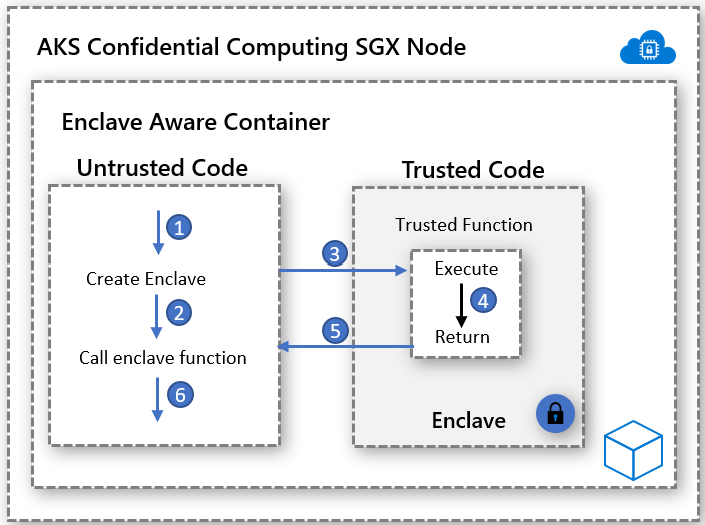
Confidential Computing
- Pourquoi aller encore plus loin ?
Tu penses que faire tourner chaque pod dans une micro-VM, c’est le top ?
Et si je te disais qu’il est aussi possible de protéger les données pendant qu’elles sont en cours de traitement, même contre l’hyperviseur ?
C’est ça, l’idée du Confidential Computing : tout ce qui tourne dans une enclave est invisible, même pour le système hôte.
- Comment ça marche ?
Grâce à des extensions matérielles de processeur, comme :
- Intel SGX
- AMD SEV
Ces technos permettent de créer des enclaves sécurisées directement dans le CPU.
C’est là que tes données sont déchiffrées et traitées, et personne d’autre n’y a accès, même pas Azure.
Pour en bénéficier, il faut utiliser des VMs spécifiques dans AKS :
- DCsv2 utilisent Intel SGX
- DCsv3 utilisent Intel SGX
- DCdsv3 utilisent AMD SEV-SNP, qui offre une protection de l’OS complet, pas seulement les enclaves
✅ Ce que ça apporte
- L’isolation est matérielle, pas logicielle.
- Tu peux répondre à des exigences très strictes en matière de sécurité (santé, finance, légal…).
⚠️ Là aussi, y’a des limites
- Cas d’usage spécifiques avec des coûts potentiellement plus élevés.
- Nécessite une compatibilité avec d’autres services Azure, ce qui peut être restrictif pour certains workloads
4.Choisir son type de compute
Bien dimensionner son cluster, c’est plus qu’un choix de VM.
C’est comprendre comment Kubernetes consomme les ressources, et comment faire cohabiter performance, coût, scalabilité et biensure stabilité
Taille et type de VM : ce que tu choisis… te suit longtemps
Lors de la création d’un cluster AKS (via le portail Azure, la CLI ou Terraform), tu fera face a ses deux choix :
- La région Azure
- La taille de VM pour chaque node pool
Ces choix est déterminants : toutes les machines d’un node pool auront la même taille, le même OS, le même type de stockage.
👉 Si tu veux mixer CPU, RAM, GPU ou stratégies de coût différentes, il faudra plusieurs node pools a deployer toute en restant dans l’optique ( Systéme , Utilisateur )
Comprendre la consommation réelle : requests, réservations, pods
Kubernetes ne planifie pas des conteneurs n’importe comment. Il s’appuie sur :
- Requests : ressources minimales qu’un pod réclame pour être planifié
- Limits : plafond qu’un pod ne doit pas dépasser (en CPU/RAM)
Mais il faut aussi prendre en compte ce que le node garde pour lui-même :
- Agents internes (kubelet, container runtime, network plugin…)
- System Pods (CoreDNS, kube-proxy…)
- DaemonSets que tu ajoutes toi-même (Fluent Bit, Prometheus, Falco…)
👉 Ces éléments consomment de la ressource réelle, mais ne sont pas visibles dans tes YAML. Si tu ne les prends pas en compte, tu risques des pods qui restent “Pending” sans explication claire.
Recommandation : toujours laisser une marge de sécurité (~10-15%). Tu peux l’ajuster avec l’expérience.
Optimiser les coûts : ne paie pas pour de l’air
Un node peu utilisé coûte autant qu’un node plein. C’est là que l’analyse de coût devient critique.
Tu peux t’appuyer sur :
Cela permet d’évaluer :
- Le coût réel par pod ou par node
- Le taux d’occupation réel (vs théorique)
- Le waste (ressources allouées mais non consommées)
| 🎯 Vise 80-90% d’utilisation effective. En dessous, tu surpaies. Au-dessus, tu frôles le throttle. |

Détails importants : max pods, sizing, et node saturation
- System Pods et DaemonSets
Ils tournent sur chaque node du cluster, consomment CPU/RAM, et doivent impérativement être intégrés dans ton sizing.
C’est souvent ce qu’on oublie quand on se dit “tiens, j’ai 2 vCPU, je vais caser 8 pods de 250mCPU”… et ça ne passe pas 😬
- Maximum de pods par node
Ce paramètre fixe est défini au moment de la création du node pool, selon le plugin réseau :
| Plugin réseau | Pods max par node |
|---|---|
| Kubenet | 110 |
| Azure CNI classique | 250 |
| Azure CNI Overlay | Jusqu’à 1000 (selon SKU et des config IPAM) |
🔍 Exemple concret :
Tu provisionnes un node pool avec des VMs XXL , disons des Standard_E64ds_v5 (64 vCPU, 504 Go RAM).Mais tu es en Azure CNI classique, avec une limite par défaut de 250 pods par node. Résultat : même si ton node a la capacité d’héberger bien plus de pods côté CPU et mémoire, tu es limité par le maxPods défini à la création du pool.En pratique, tu risques de n’utiliser que 30-40% des ressources réelles de la machine… tout en payant le prix fort pour une instance haut de gamme. 💸 Conclusion : c’est un mauvais sizing, causé par un oubli de contrainte réseau. |
Scalabilité intelligente : faire grossir ce qu’il faut, quand il faut
- Scaling des nodes (Cluster-wide)
Manual Scaling
- Tu définis un nombre fixe de nodes.
- Simple et prévisible.
- Mais pas flexible : si tu prends une charge inattendue ou perds un node, tu es coincé.
Cluster Autoscaler
- AKS gère automatiquement l’ajout et le retrait de nodes en fonction des pods qui ne peuvent pas être planifiés.
- Très efficace quand tu combines avec HPA.
- Fonctionne avec des taints, affinities, sur plusieurs node pools.
⚠️ Les limites
- Les nodes ne sont supprimés que si tous les pods sont evictable (
podDisruptionBudget,tolerations,taints, etc.). - Il faut configurer des paramètres comme
scale-down-unneeded-timepour ajuster la réactivité du scaling automatique à la baisse
- Scaling des pods
Manual scaling (replicas: x)
- Tu fixes à la main le nombre de pods.
- Idéal pour les charges constantes (par exemple une API d’administration interne).
HPA – Horizontal Pod Autoscaler
- Ajuste le nombre de pods en fonction de l’usage CPU/RAM ou d’une métrique custom.
- Parfait pour les applis frontend ou des API exposées publiquement.
KEDA – Kubernetes Event-driven Autoscaler
- Déclenche le scaling en réponse à des événements externes : taille d’une queue Azure, messages Kafka, webhooks, etc.
- Parfait pour du batch, de l’event-driven ou du job court.
VPA – Vertical Pod Autoscaler
- Pourquoi c’est utile ?
Parfois, scaler en largeur ne suffit pas : un pod mal dimensionné reste inefficace, même en 20 exemplaires.
Le VPA observe ton pod, analyse sa consommation, et ajuste dynamiquement ses requests et limits.
Trois modes :
Off: observe et recommandeInitial: applique une recommandation au 1er déploiementAuto: met à jour automatiquement (et redémarre le pod si besoin)
⚠️ Le VPA n’est pas compatible avec le HPA sur les mêmes ressources (cpu, memory). |

Virtual Nodes & Azure Container Instances
- C’est quoi l’idée ?
Tu as un pic de charge, mais tu ne veux pas attendre que le Cluster Autoscaler crée un node ?
Tu veux pouvoir déployer un pod instantanément, sans te soucier de l’infra ?
👉 C’est ce que permettent les Virtual Nodes, grâce à Azure Container Instances (ACI).
- Pods planifiés sur un “node virtuel” branché au cluster
- Provisionnement en quelques secondes
- Pas de gestion de VM côté client
| ⚠️ À savoir: – Les virtual nodes ne supportent pas les volumes persistants, donc à exclure pour tout workload stateful – Azure annonce le remplacement progressif des virtual nodes au profit d’Azure Container Apps – Donc les Virtual Nodes via ACI sont encore supportés. Mais Container Apps devient le recommandé pour du burst stateless |
Cas d’usage
- Débordement de charge temporaire (overflow)
- CI/CD, jobs éphémères
- “Buffer zone” pendant les pics inattendus

🔄 Petit retour perso :
jusqu’ici, je n’ai jamais recommandé l’usage des Virtual Nodes à un client.
Non pas que la techno soit inutile — elle peut avoir du sens sur des cas très ponctuels — mais dans la pratique, on trouve souvent des alternatives plus fiables, plus prévisibles, ou simplement plus faciles à intégrer
Mais je suis curieux ! Si jamais l’un ou l’une d’entre vous a mis ça en place en prod ou dans un contexte précis, je suis preneur de votre retour … ça m’intéresse 👇
| ⚠️ À savoir: Comme toujours dans le cloud : “Pay as you go” ≠ “Pay sans réfléchir” 💸 |
5.Choix du système d’exploitation
Kubernetes tourne majoritairement sur Linux, mais Azure te laisse quand même le choix entre plusieurs OS possibles dans AKS.
Et même si ça peut sembler anodin, le choix de l’OS impacte :
- la compatibilité avec certaines fonctionnalités K8s,
- le support de pilotes spécifiques (GPU, sécurité),
- la fréquence des mises à jour,
- voire les coûts associés.
Ubuntu 22.04
Ubuntu 22.04 est le système d’exploitation par défaut pour les pools de nœuds Linux dans AKS.
Cette version est largement adoptée pour sa stabilité et sa vaste compatibilité.
Avantages :
- 🟢 Cycle de mise à jour régulier
- 🟢 Large compatibilité : Fonctionne avec une multitude d’outils et d’extensions AKS
- 🟢 Support étendu
Azure Linux
Azure Linux est une distribution Linux Open-source développée par Microsoft
Avantages :
- 🟢Optimisation pour Azure : Offre des performances accrues pour les charges de travail sur Azure.
- 🟡Support des GPU : Compatible avec les GPU NVIDIA V100 et T4, facilitant les charges de travail nécessitant une accélération matérielle. Toutefois, le support pour les séries NC A100 v4 n’est pas disponible
Limitations :
- 🔴 Support AppArmor : Actuellement, Azure Linux ne supporte pas AppArmor. Cependant, il supporte SELinux, qui peut être configuré manuellement.
- 🔴 Disponibilité limitée : Principalement conçu pour être utilisé sur Azure ; la disponibilité on-premises ou sur d’autres plateformes n’est pas garantie
Choix recommandé :
Basé sur l’actualité des releases et la compatibilité avec les solutions partenaires, Ubuntu 22.04 est préféré pour son dynamisme et sa fiabilité.
Windows (cas très limité)
AKS prend en charge les node pools Windows, principalement pour des applications qui nécessitent Windows Server
Cas d’usage restreint :
- Réservé aux applications qui ne supportent pas .NET Core (uniquement .NET Framework).
Contraintes à bien connaître
- 🔴Complexité de déploiement :
- Déploiement plus lourd (images, démarrage, redémarrage des nodes)
- Gestion des pods
hostProcessspécifique
- 🔴Support GPU ? Oui, mais partiel :
- Les pools Windows avec GPU sont désormais supportés (ex. séries NVv4 avec GPU AMD ou NVIDIA)
- Mais la configuration est plus complexe
- 🔴Coût élevé :
- Coûts supplémentaires liés à la location de licences et des capacités de compute.
| 💡 Recommandation Dans 95 % des cas, le choix le plus simple et le plus sûr, c’est Ubuntu 22.04 Il est stable, compatible avec tous les outils AKS, bien documenté, et largement utilisé dans l’écosystème Kubernetes. sauf si un besoin client ou technique t’oblige à faire autrement |
6.Design des Node Pools
Un seul type de node ne suffit pas. Pour que ton cluster AKS soit vraiment efficace, résilient, et optimisé côté coûts et performances, il te faut une vraie stratégie de “node pooling”.
Pourquoi plusieurs node pools ?
Créer un seul node pool pour tout faire, c’est s’exposer à plein de problèmes : surcharge, conflit de ressources, manque de scalabilité
Objectifs principaux :
- 🟢Isoler les workloads : les pods système (CoreDNS, kube-proxy…) ne doivent pas “grignoter” la capacité des applications.
- 🟢Utiliser du compute adapté : GPU, disques éphémères, VM haute mémoire, etc.
- 🟢Respecter les contraintes de sécurité : certains workloads nécessitent des nœuds conformes à des règles spécifiques (chiffrement, FIPS…).
- 🟢Reduction des coûts : certains pools peuvent être scalés à 0 (mode pause) quand les workloads ne tournent pas
- 🟢Segmenter le scaling : chaque pool peut être scalé indépendamment, manuellement ou automatiquement
- 🟢Faciliter la maintenance : upgrade progressif, déploiement canari ….etc
Deux types de Node Pools : System & User
1.System Node Pool
C’est le cœur technique du cluster. Il héberge les composants essentiels de Kubernetes, et ne doit jamais contenir d’applications.
Caractéristiques :
- Rôle : Cluster core uniquement, pas d’applications
- OS : Ubuntu recommandé
- Sizing recommandé : 2 nodes minimum, 3 pour profiter des Availability Zones
- Taint recommandé :
CriticalAddonsOnly=true:NoSchedule - Scaling : start en
manual scale, puis passe enCluster Autoscalerdès que possible
| 🧠 Dans cet exemple, on part volontairement sur du manual scaling. Pourquoi ? Parce que quand on ne connaît pas encore la charge réelle du client, il vaut mieux commencer simple. Tu observes, tu dimensionnes, tu ajustes ensuite. Une fois les besoins connus, tu pourras activer l’autoscaling avec les bons paramètres, sans stress. |
2.User Node Pool
C’est là que tournent tes applications et autre
Caractéristiques :
- Rôle : héberger les pods lié a votre application
- OS : Ubuntu recommandé
- Scaling : start en
manual scale, puis passe enCluster Autoscalerdès que possible ( une fois le dimensionnement stabilisé) - Sizing recommandé : 2-3 nodes pour commencer, répartis sur 3 Zones Azure
- Taint recommandé :
app=true:NoSchedule
Recommandations :
- Ajoute des taints/tolerations pour isoler les workloads critiques
- Répartis sur 3 zones de disponibilité pour éviter les SPOF
3.GPU Node Pools ( Bonus )
C’est un node pool spécialisé, dédié aux workloads qui nécessitent de la puissance de calcul accélérée.
Il est conçu pour exécuter des tâches comme le machine learning, le traitement d’image/vidéo, ou encore le calcul scientifique (HPC).
Caractéristiques :
- Rôle : héberger des pods qui exploitent les capacités GPU
- OS : Ubuntu 22.04 (meilleure compatibilité avec les drivers NVIDIA)
- Scaling : manuel ou automatique, avec la possibilité de scaler à zéro pour économiser quand les workloads ne sont pas actifs
- Taint recommandé :
gpu=true:NoSchedule
| ⚠️ Attention sur les coûts : Les nœuds GPU sont très coûteux (souvent 5 à 10 fois plus chers qu’un nœud standard). Si tu ne gères pas bien l’autoscaling, la facture peut vite s’envoler. 👉 Active toujours le scaling à zéro quand le GPU n’est pas utilisé, et surveille les métriques de consommation. |
Node Affinity & Anti-Affinity
Cette fonctionnalité de Kubernetes permet de contrôler précisément où sont déployés les pods, en fonction des caractéristiques des nœuds (labels, zones, rôles, etc.).
Objectif :
- Node Affinity : tu attires certains pods vers des nœuds spécifiques (ex : avec label
workload=gpu). - Node Anti-Affinity : tu évites que certains pods soient déployés ensemble (ex : deux réplicas critiques sur le même nœud).
Cas d’usage typiques :
- Isoler des workloads sensibles sur des nœuds dédiés
- Répartir des réplicas d’une app entre plusieurs nœuds pour limiter les risques de SPOF
- Optimiser le placement dans des environnements multi-AZ, en forçant la répartition et la resilience

PROCHAIN ARTICLE
👉 Dans la seconde partie de cet article, on entre dans un sujet incontournable pour tout architecte AKS : la maîtrise du WASTE
Au programme :
- Stratégies pour réduire les coûts (Reserved, Spot, scaling intelligent)
- Design efficace des clusters (nombre, type, et répartition des node pools)
- Visibilité des coûts avec OpenCost et l’add-on AKS natif
- Et bien plus encore…
📎 Pour aller plus loin (docs Microsoft) :
- Use multiple node pools in AKS
- AKS Node configuration and best practices
- AKS system and user node pools explained
- Isolate workloads with Kata Containers (sandboxed containers)
- Confidential nodes and VMs for AKS
- Cluster Autoscaler in AKS
- Horizontal Pod Autoscaler (HPA)
- KEDA (event-driven autoscaling)
- Vertical Pod Autoscaler (VPA)
- Azure Linux for AKS
- Ubuntu on AKS
- Virtual Nodes in AKS with ACI
🙏 Remerciements
Cet article prolonge des échanges issus de plusieurs workshops conduits par Benoît Sautierre, dont la vision et l’animation ont largement nourri les réflexions présentées ici. Expert engagé et passionné, il a su créer un cadre de réflexion stimulant, pour lequel je lui adresse mes plus vifs remerciements.