
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
📋 Dans cet article
- Régional ou Zonal ?
- Legacy ou Cloud-ready ?
- Windows ou Linux ?
- Latence entre zone : un frein réel
- Répartition & haute disponibilité
- Topologie Réseau & Dépendances DNS
- Alignement des disques & performances IOPS
- Identités & règles d’accès post-bascule
- Application Security Groups (ASG)
- Azure Backup
- Recovery Services Vault (RSV)
- Azure Site Recovery (ASR)
- Exemple type d’architecture PCA mono-zone
2. PROBLÉMATIQUE
« Quand ton infra tombe, ce ne sont pas des machines qu’on doit redémarrer, mais un service métier complet, attendu par des clients, des agents, des équipes »
Anticiper l’incident, c’est notre job. Et quand il s’agit d’infrastructure IaaS, la vraie question n’est pas “est-ce que c’est sauvegardé ?”, mais “combien de temps on met pour redémarrer proprement ?”
Un PCA (Plan de Continuité d’Activité) ou PRA (Plan de Reprise) bien conçu, c’est une question de choix techniques lucides dès le départ : architecture, contraintes applicatives, cohérence des dépendances, gouvernance des sauvegardes et design des scénarios de bascule.
Ce premier article pose la base de ces arbitrages, avec du concret terrain et des points critiques à adresser en amont
3. ARBITRAGES CLÉS
Avant d’ouvrir Azure Site Recovery ou de cliquer sur Backup Vault, il faut clarifier plusieurs choix structurants :
Régional ou Zonal ?
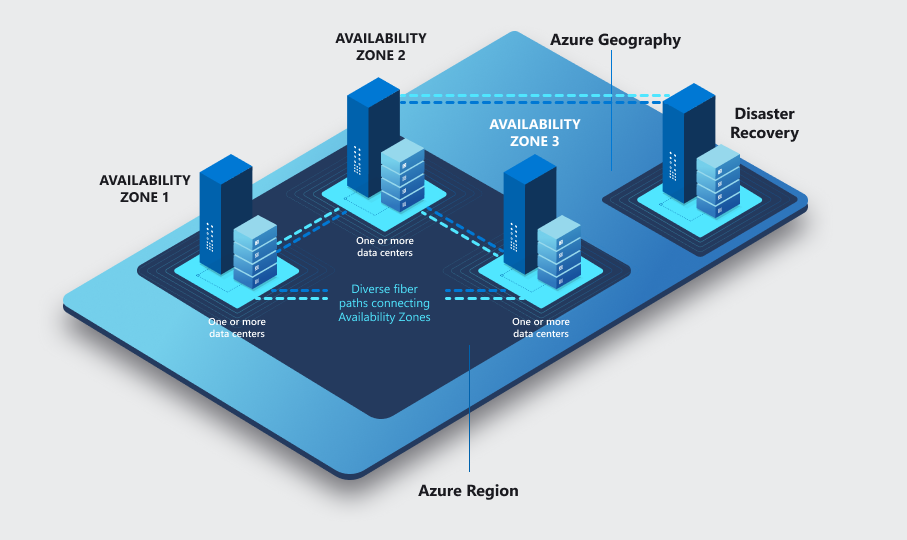
- Zonal : réplication dans une autre Zone de la même Région
- Régional : réplication vers une autre Région
Legacy ou Cloud-ready ?
Il faut cartographier : qui parle à qui, et quelles sont les dépendances critiques intra-Zone ou inter-Zone ?
Signaux à surveiller côté legacy :
- Connexions codées en dur à des IP privées
- Pas de DNS interne ou usage massif de
/etc/hosts - Aucun gestionnaire de secrets (variables d’environnement, fichiers plats)
- Couplage fort entre application et base de données (latence critique, mêmes AZ nécessaires)
- Dépendances techniques non documentées ou héritées (ports spécifiques, configurations locales)
Cloud-ready : API stateless, DB managée, gestion centralisée des secrets, DNS interne, infrastructure modulaire et documentée
Windows ou Linux ?
- Windows : intégration plus poussée avec Azure Backup (agent VSS, support SQL Server IaaS)
- Linux : plus léger à répliquer mais attention à la cohérence applicative
| ⚠️ Attention : Certaines distributions ou noyaux custom peuvent poser problème avec les agents Azure ou ASR (ex. no kernel support for Hyper-V sockets, modules manquants, etc.) Toujours vérifier la compatibilité avec ASR |
Latence entre zone : un frein réel
Exemple réel : une application dans AZ1 avec base de données dans AZ2 → les utilisateurs remontent des lenteurs.
👉 Ce type d’observation impacte l’architecture cible :
- 🔴 PCA multi-zone à éviter si les workloads sont trop sensibles à la latence inter-Zone
- 🟢 Préférer un PCA mono-zone avec VMSS flex : un par Zone, et bascule via ASR uniquement si nécessaire
Répartition & haute disponibilité

- Availability Set : pas compatible Capacity Reservation avec ASR
- Availability Zone : recommandé pour production stable
- VMSS Flex : pour PCA mono-zone
| ⚠️ Attention : – VMSS Flex n’est pas compatible avec Ultra Disk |
Topologie Réseau & Dépendances DNS
- La réplication sans prise en compte du vNet, NSG, DNS ou routage custom = PCA Incomplet
- Le réseau de la zone ou région cible doit être prêt à accueillir les VM répliquées
| ⚠️ Problème courant : tout est répliqué, mais rien ne répond → DNS KO, UDR manquants, IPs invalides |
Recommandation :
Network Mapping : utilisez le mapping automatique ou manuel pour associer chaque vNet/source à un vNet/cible (-asr suffix), ce qui permet une bascule IP transparente en cas de failover
Adresse IP : ASR respecte l’usage DHCP ou l’IP statique. Si statique, assurez-vous que cette IP est valide dans la zone cible .
NSG & sécurité réseau :
- Utilisez les service tags AzureSiteRecovery, Storage, Microsoft Entra ID, ServiceBus, et Automation pour autoriser le trafic sortant nécessaire
- ND : les appliances réseau (NVA) ne doivent pas bloquer le trafic ASR. Préférez le Service Endpoint Microsoft.Storage pour les VM sources
Test de bascule : réalisez des tests sans impact en validant que chaque VM répliquée rejoint le bon vNet et que la connectivité DNS/IP est fonctionnelle
| 💡 Cette section fera l’objet d’un focus avec des scripts PowerShell concrets dans une prochaine partie |
Alignement des disques & performances IOPS
- ASR réplique les disques, mais ne garantit pas le tier : une VM initialement sur un Premium SSD peut, après failover, se retrouver sur un standard SSD ou HDD, entraînant une chute notable de performance
- Pour les Premium SSD, Azure permet de changer manuellement le performance tier (par exemple de P10 à P50) sans downtime, mais uniquement lorsque le disque est déjà créé
Risques :
- Disques répliqués avec moins d’IOPS/throughput → lenteurs appréciables, même si les VM démarrent.
- Un dimensionnement inadapté peut entraîner de mauvaises surprises au moment du failover
🛑 NB : les capacity reservations et réservations de SKU disque seront traitées dans les prochains articles.
Identités & règles d’accès post-bascule
Les Managed Identities (MSI) associées aux machines virtuelles répliquées ne changent pas d’ID après failover.
Mais attention : leur accès aux ressources Azure reste dépendant des rôles RBAC attribués, qui eux, sont liés au scope (groupe de ressources, subscription, etc.) d’origine.
📌 Exemple courant : la VM redémarre dans la région cible, mais :
- Elle n’a plus accès au Key Vault, Azure Container Registry ou Azure Service Bus,
- Parce que les attributions de rôle étaient faites au niveau du groupe de ressources local, et pas dans le scope cible.
Bonnes pratiques :
- Préférer des attributions RBAC au niveau Subscription ou Management Group, pour garantir la persistance des accès après basculement
- Intégrer des étapes post-failover dans les Recovery Plans (ou scripts personnalisés) pour réassigner les rôles si nécessaire
- Vérifier les dépendances critiques (Key Vault, Storage, EventHub…) et tester les scénarios de reprise avec
az role assignment listou via Azure Policy
Application Security Groups (ASG)
Les Application Security Groups (ASG) permettent de simplifier la gestion des règles NSG en regroupant des machines virtuelles par rôle applicatif, sans gestion d’IP explicite.
| ⚠️ ASR ne réplique pas les ASG : Même si la VM et ses interfaces réseau sont bien restaurées dans la région cible, les ASG référencés dans les règles NSG doivent être recréés manuellement ou via automatisation |
📌 Risques observés :
- VM en ligne, mais aucun trafic réseau entrant/sortant
- NSG bien présent, mais ASG manquant → règle ignorée
Recommandation :
- Intégrer la création ou restauration des ASG dans un process automatisé de type Recovery Plan
- Tester la connectivité post-failover sur les ports critiques protégés par ASG
💡 Ce sera couvert dans un prochain article :
Je partagerai un script PowerShell qui extrait dynamiquement les ASG d’une région source, puis les réimporte dans la région cible avant le failover.
Objectif : zéro surprise réseau pendant la bascule
4. AZURE BACKUP, RSV ET SITE RECOVERY
Azure Backup
Azure Backup offre une protection granulaire des ressources IaaS, couvrant :
- les machines virtuelles complètes (disques + configuration),
- les fichiers et dossiers spécifiques (via MARS agent),
- les workloads applicatifs comme SQL Server ou SAP HANA en IaaS.
🔄 La sauvegarde est orchestrée automatiquement, avec des points de restauration réguliers selon la politique définie :
- Sauvegardes de bases SQL avec full, diff et log backups (si l’extension est installée)
- Snapshots disque à chaud
Recommandation :
- Installer l’IaaS Extension SQL sur les VMs SQL pour gérer automatiquement les sauvegardes applicatives (full, diff, log) sans scripts personnalisés
- Définir une stratégie de rétention claire selon la criticité métier (30j, 1 an, 10 ans avec vault de longue durée, etc.)
👉 Documentation officielle SQL IaaS Backup
Recovery Services Vault (RSV)
- Conteneur pour centraliser les politiques de sauvegarde & réplication
- Types de redondance :
- LRS : local (coût faible, recommandé pour tests/dev)
- ZRS : redondance inter-zone (bon compromis PCA zonal)
- GRS : réplication régionale (coûteux mais robuste)
Recommandation terrain :
- Mutualiser un RSV ZRS pour la production, LRS pour les environnements hors production
📌 Pour une meilleure mutualisation des RSV entre plusieurs projets, une gouvernance par tags de criticité permet d’automatiser les choix :
criticalite=haute→ la VM est protégée dans un RSV GRScriticalite=moyenne→ RSV ZRScriticalite=faible→ RSV LRS
Cela permet à chaque équipe de piloter ses besoins PCA sans réinventer la roue
| ⚠️ Attention : changer une VM de RSV réinitialise son historique de sauvegarde |
🔁 Pour aller plus loin, on peut aussi taguer la politique de rétention et de fréquence des sauvegardes (ex. backup_policy=hebdomadaire, backup_retention=30j, backup_time=23h00).
- Conteneur pour centraliser les politiques de sauvegarde & réplication
- Types de redondance :
- LRS : local (coût faible, recommandé pour tests/dev)
- ZRS : redondance inter-zone (bon compromis PCA zonal)
- GRS : réplication régionale (coûteux mais robuste)
Azure Site Recovery (ASR)
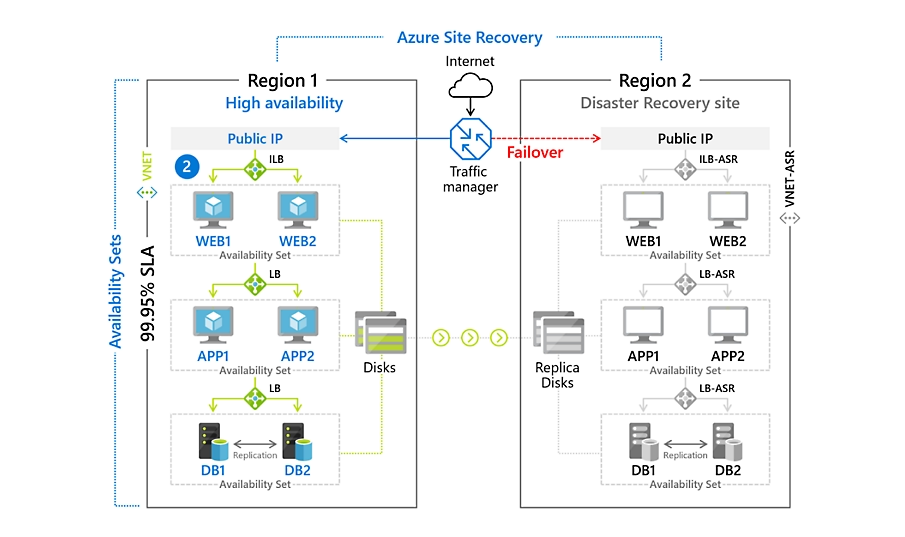
- Réplication automatisée des VMs vers une autre zone ou région
- Prise en charge de scénarios zonal / régional
- Orchestration complète avec :
- Plan de récupération
- Scripts personnalisés (PowerShell, Azure CLI)
- Gestion des NICs, IPs, NSG, etc.
➡️ ASR gère la continuité du service (failover, reprotect), là où Azure Backup protège les données.
📌 En pratique, les deux sont complémentaires :
- Azure Backup = protection de la donnée, restaurable à tout moment
- ASR = maintien de l’activité, orchestration en cas d’interruption majeure
5. ERREURS COURANTES
- 🔴 Réplication d’une VM sans sa base → latence, ou crash applicatif
- 🔴 Usage d’Availability Set avec ASR → incompatibilité Capacity Reservation
- 🔴 Zones mal gérées → ASR réplique, mais réseau et DNS sont KO
Exemple type d’architecture PCA mono-zone
| Zone | VMSS Flex | DB | RSV | Backup | ASR |
|---|---|---|---|---|---|
| AZ1 | ✅ | ❌ | ZRS (prod) | Agent installé | vers AZ2 |
| AZ2 | ❌ | ✅ | Agent installé | vers AZ1 |
6. CONCLUSION
📌 Ce que l’on oublie souvent : Le failover, c’est 50 % technique… 50 % coordination. Sans documentation claire, sans runbook testé, même un PCA parfait techniquement peut échouer.
Un bon PCA IaaS commence par une cartographie honnête de la réalité technique, et une série d’arbitrages clairs sur :
- Zones et régions
- Applications legacy vs modernes
- OS & dépendances réseau
- Performances & contraintes éditeurs
🧱 Ensuite viennent les outils : Azure Backup pour la donnée, ASR pour le run, RSV pour piloter l’ensemble.
PROCHAIN ARTICLE
Qui on redémarre en premier ? Et pourquoi.
Un PCA, ce n’est pas une simple question d’infrastructure
C’est savoir qui doit pouvoir bosser dans les 30 minutes, et quel service métier coûte vraiment cher s’il tombe
👉 Dans la prochaine partie, on verra comment travailler avec les métiers pour identifier les rôles critiques, cartographier les blocs fonctionnels à prioriser, et bâtir des scénarios de bascule qui font sens techniquement et financièrement.
📎 Pour aller plus loin (docs Microsoft) :
- Azure Site Recovery – Documentation officielle
- Prérequis et limitations ASR pour les VM Azure
- Sauvegarde Azure pour machines virtuelles IaaS
- SQL Server IaaS Agent Extension pour Backup
- Mapping Réseau et IP pour ASR
- Gestion des disques et performance tiers avec ASR



