
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
📋 Dans cet article
- Flux
- ArgoCD
- Comparatif Flux vs ArgoCD
- Pourquoi l’observabilité est bien plus que du monitoring
- L’approche Microsoft : un socle, plusieurs briques
- Stack unifiée Azure-native
- Corrélation intelligente
- Container Insights : plug-and-play
- Multi-profils, multi-usages
- Observabilité réseau
- Azure Monitor Workspace (Prometheus)
- Azure Managed Grafana
- Azure Diagnostic Settings
- Une stack 100% open source, 100% maîtrisée
- Loki : le Prometheus des logs
- Mais ça a un prix : la maintenance
- Et en cas de crash ?
- Exporters, configmaps et alerting
- Self-managed : gain d’autonomie, coût caché
2. PROBLÉMATIQUE
« Avoir des dashboards, c’est bien. Garder le contrôle, c’est mieux. »
Tu peux avoir Grafana, des logs, des dashboards dans tous les sens…
Mais si tu ne sais pas où chercher, quoi corréler, ou comment garder ton cluster aligné avec Git, tu restes dans le flou.
Et c’est souvent ce qui se passe.
Trop d’outils, trop de signaux, pas de stratégie claire.
Tu passes plus de temps à naviguer entre les consoles qu’à comprendre ce qu’il se passe vraiment.
C’est là qu’il faut faire un choix :
- Tu veux du managé et bien intégré ? L’écosystème Azure est prêt
- Tu veux tout maîtriser ? La stack open source (Prometheus, Grafana, Loki) est là
- Et entre les deux, GitOps devient ta vérité unique pour garder le cap
Dans cette seconde partie, on parle supervision qui tient la route
pas de “monitoring pour faire joli” mais pour agir au bon moment, sur les bons signaux
4. GITOPS
L’époque où on lançait un kubectl apply -f depuis son poste est (presque) révolue
Aujourd’hui, on parle de GitOps : un modèle où le cluster va chercher lui-même ce qu’il doit exécuter, directement dans un dépôt Git versionné
Et ce simple renversement change tout :
✔ Ce n’est plus un humain qui pousse. C’est le cluster qui tire.
Flux
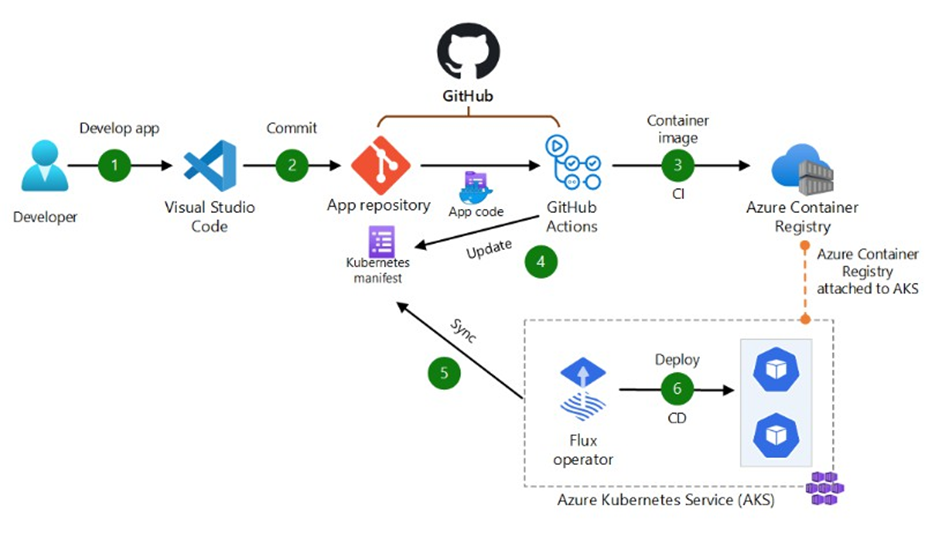
Flux, c’est la solution adoptée et maintenue par Microsoft dans AKS, disponible directement en extension AKS ou Arc-enabled.
Il s’appuie sur une philosophie très claire :
🎯 « The Git repository is the source of truth. »
📌 Fonctionnement :
- Chaque cluster lit une ou plusieurs branches Git (par exemple
mainouprod) - Dès qu’un commit est validé (ex: une PR fusionnée), le cluster déclenche un déploiement
- Tout écart avec l’état du dépôt est corrigé automatiquement
Et surtout :
- Si quelqu’un modifie un objet à la main (via portail, CLI…), Flux le remet en l’état attendu, car seule la vérité Git fait foi
Et pour gérer plusieurs environnements ?
Tu vas vite avoir besoin d’un outil pour adapter dynamiquement les manifests en fonction de l’environnement (dev, recette, prod…).
C’est là que Kustomize entre en jeu.
Kustomize te permet de :
- Réutiliser une base commune de manifests (base.yaml)
- Et d’appliquer des overlays selon l’environnement (par exemple un replicaCount=1 en dev, et =3 en prod)
- Sans avoir besoin de réécrire ou de cloner tous tes fichiers
Kustomize est natif dans kubectl et compatible avec Flux et ArgoCD
Il fonctionne sans Helm, ce qui le rend simple à auditer et facile à maintenir.
Tu peux aussi le combiner avec des patchesStrategicMerge pour des différences plus fines
✅ Avantages :
- Intégration native avec Azure (extension officielle)
- Maintenance assurée par Microsoft
- Parfait pour déployer du Kubernetes pur
- Idéal pour gérer le drift et verrouiller les environnements
| ⚠️ Mais : Flux ne voit que Kubernetes. Il ne sait pas orchestrer d’autres briques (Azure SQL, Key Vault, Terraform, etc..) |
ArgoCD
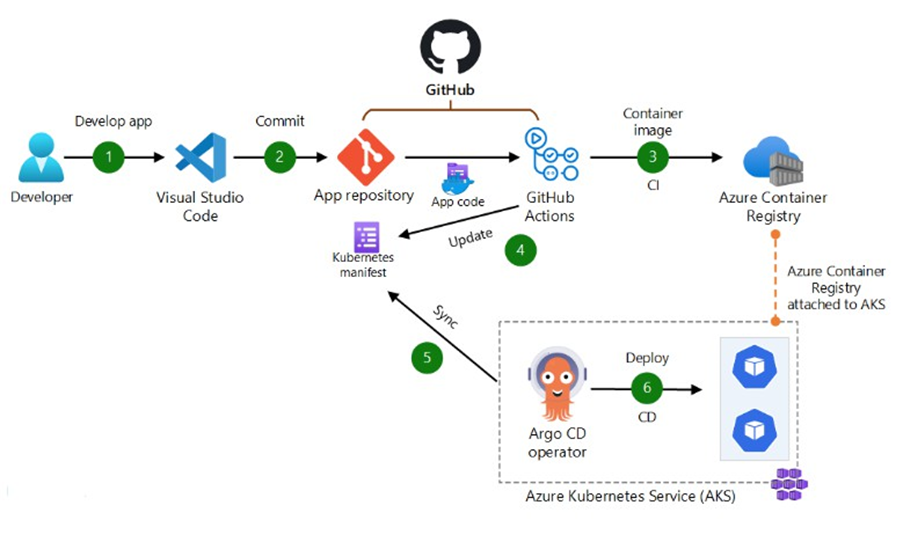
ArgoCD, c’est un autre monde.
Pas seulement plus “user friendly” => plus ouvert, plus large
Contrairement à Flux :
- Ce n’est pas juste une extension à activer
- C’est une application à déployer (souvent via Helm chart)
- Et c’est une vraie plateforme de delivery GitOps
Ce que propose ArgoCD :
- UI intégrée (portail de pilotage GitOps)
- Visualisation des ressources, des sync, des drifts
- Système de hooks, de priorisation, de synchronisation manuelle ou automatique
- Plugins pour étendre le comportement natif
💬 Pour certains, l’existence d’une UI est un argument fort.
Pour d’autres, c’est déjà un signal de complexité
Kustomize est aussi pris en charge nativement par ArgoCD
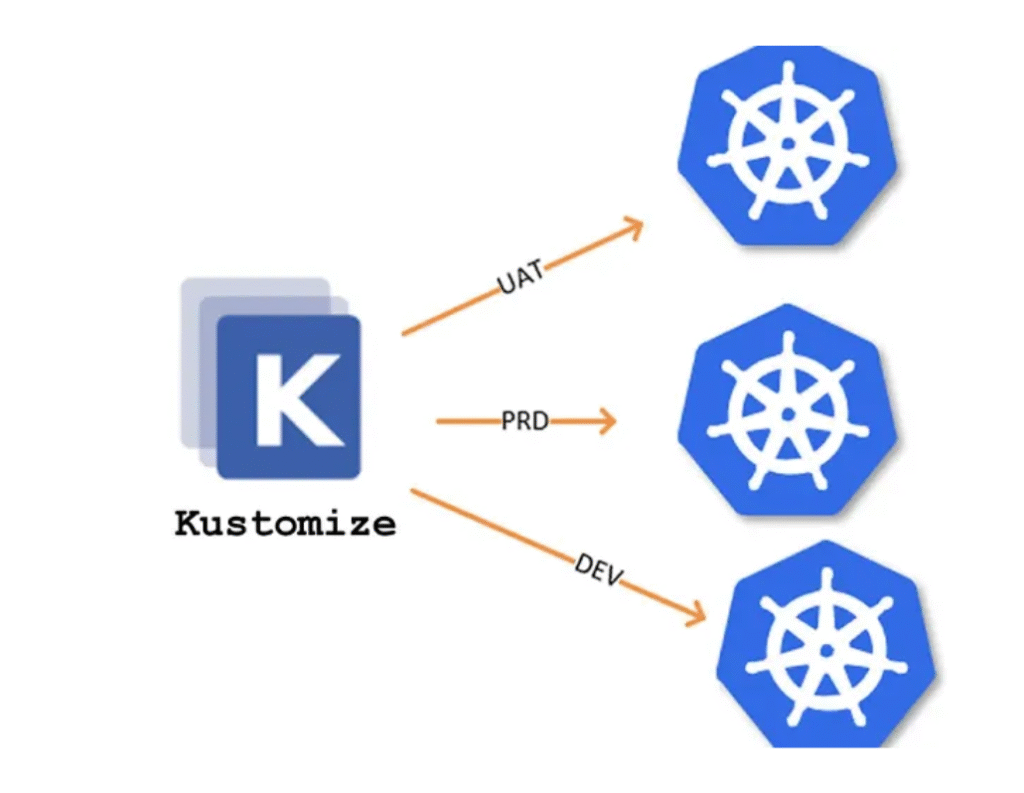
Il devient vite un incontournable quand tu dois :
- Gérer plusieurs environnements avec des différences subtiles
- Appliquer des labels, annotations ou ressources spécifiques à chaque contexte
- Garder une hiérarchie claire entre base et environnements
💬 Si tu veux une stack simple, sans trop d’abstraction, Kustomize est une excellente alternative à Helm
👉 ArgoCD est très adapté quand :
- Tu veux une interface de supervision GitOps
- Tu gères plus que du K8s ou des dépendances multi-environnement
- Tu as des équipes dédiées à l’observabilité et au delivery
Comparatif Flux vs ArgoCD
| Critère | Flux | ArgoCD |
|---|---|---|
| Complexité | Distribué sur plusieurs entités | Centralisé, tout-en-un |
| Intégration Kubernetes | Pattern Operator natif | Autonome, fonctionne à côté de K8s |
| Extensibilité | Très limitée (Kubernetes only) | Plugins et hooks disponibles |
| UI | Non | Interface Web riche intégrée |
| Orchestration | Dépendances explicites via dependsOn | Priorisation de synchronisation |
| Vision | GitOps pour Kubernetes et uniquement K8s | GitOps comme orchestrateur d’environnement |
4. OBSERVABILITÉ –> VISION MICROSOFT
L’observabilité, ce n’est pas juste “voir ce qui se passe”.
C’est donner les moyens aux équipes de comprendre, corréler, agir, et anticiper, grâce à trois piliers fondamentaux :
- 📊 Métriques
- 📁 Logs
- 📈 Traces
Et chez Microsoft, la vision de l’observabilité est en train de se stabiliser (après plusieurs itérations), autour d’une stack cohérente et intégrée : Azure Monitor
Pourquoi l’observabilité est bien plus que du monitoring
La grande différence entre monitoring et observabilité, c’est la corrélation.
Tu ne veux pas juste savoir qu’un pod crash.
Tu veux savoir pourquoi, dans quel contexte, et si cela impacte ton business.
Un pic CPU à 100% ?
Ce n’est pas juste un signal technique.
C’est peut-être un utilisateur qui abandonne son panier d’achat.
L’observabilité bien pensée permet de lier des KPI techniques à des KPI métier.
Et c’est pour ça qu’elle ne concerne pas que les Ops ou les Devs : toute l’organisation est concernée.
L’approche Microsoft : un socle, plusieurs briques
Depuis plusieurs années, Microsoft consolide sa vision sous l’umbrella Azure Monitor, qui regroupe :
| Brique | Rôle |
|---|---|
| Log Analytics Workspace | Puits de logs et moteur KQL |
| Managed Prometheus | Collecte de métriques cloud-native |
| Container Insights | Supervision des clusters AKS |
| Application Insights | Traces applicatives (via instrumentation SDK) |
| Azure Managed Grafana | Visualisation unifiée |
💡 Derrière tout ça, l’objectif est de permettre une corrélation intelligente entre les signaux, et une expérience de monitoring unifiée, même si les sources sont hétérogènes.
Stack unifiée Azure-native
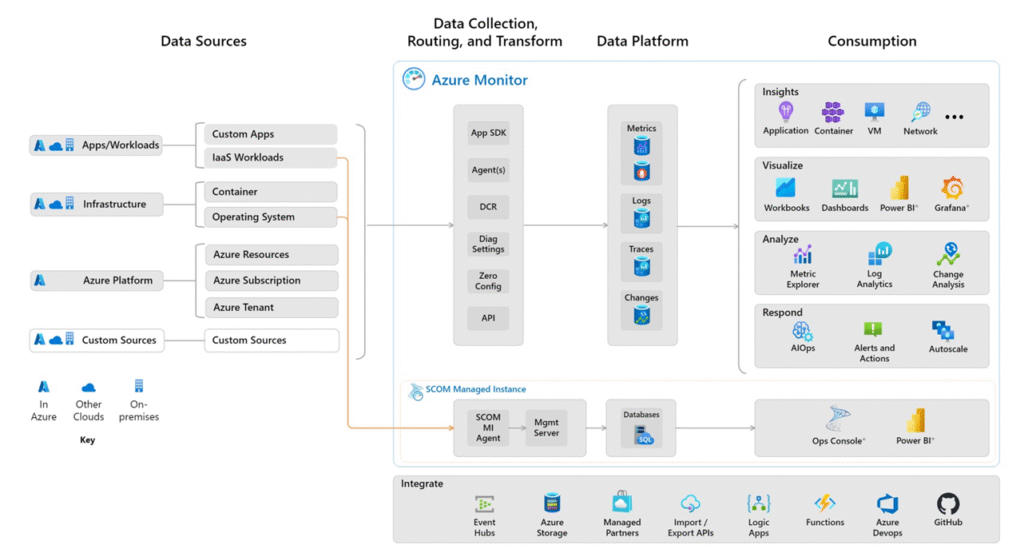
Tout commence par l’activation des diagnostic settings sur les services Azure.
Dès que c’est en place, logs, métriques et traces peuvent être redirigés vers un Log Analytics Workspace, ou une instance Prometheus managée (Azure Monitor workspace).
🌀 Ce composant devient le socle d’agrégation, sur lequel viennent se brancher les outils de visualisation comme :
- Azure Dashboards
- Workbooks
- Azure Managed Grafana
Corrélation intelligente
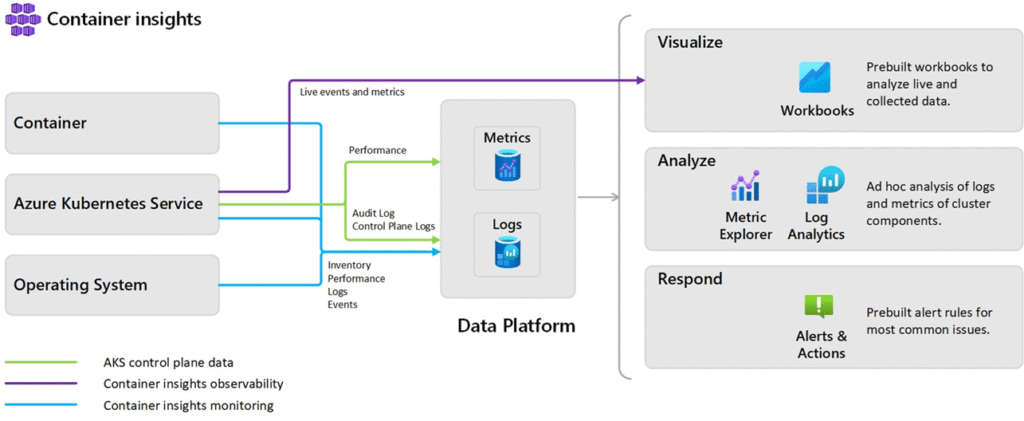
Les clusters Kubernetes génèrent beaucoup de signaux, parfois trop.
Et Microsoft l’a bien compris :
Sans stratégie, un Log Analytics peut coûter plus cher que le cluster lui-même.
Il faut donc :
- Collecter à plusieurs niveaux : control plane, nodes, pods
- Filtrer intelligemment les sources (ex.
kube-apiserver,etcd,scheduler, etc.) - Adapter les profils de collecte (→ penser au minimal ingestion profile)
Container Insights : plug-and-play
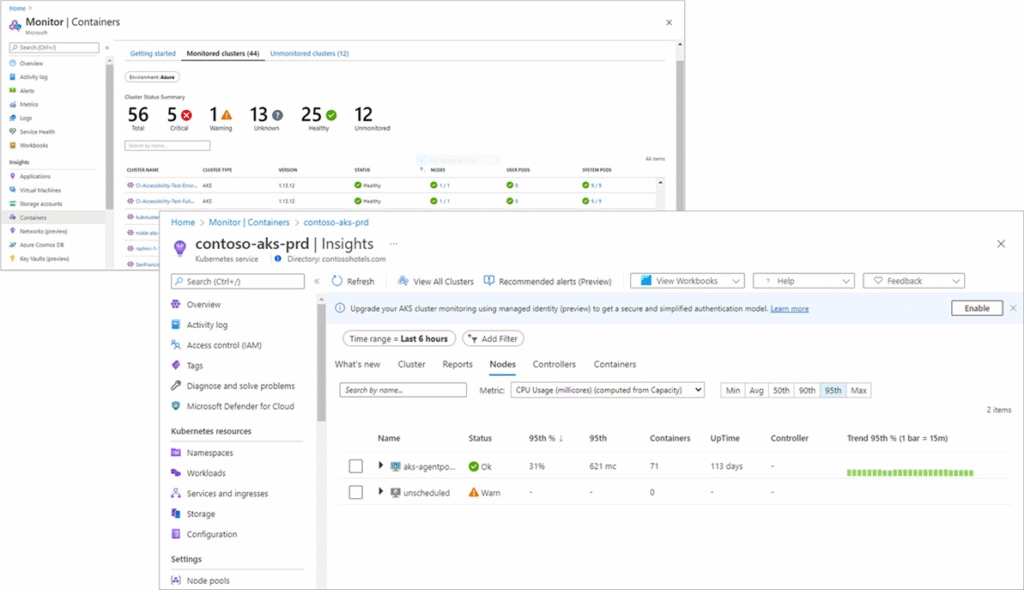
Activable en un clic depuis Azure ou via Terraform, Container Insights :
- Déploie un DaemonSet sur chaque nœud
- Collecte les métriques et logs du cluster
- Envoie les données vers Azure Monitor workspace
Il fournit :
- Des Workbooks prêts à l’emploi
- Des métriques par pod, namespace, workload
- Une expérience intégrée dans le portail Azure (⚠️ nécessite un accès réseau pour les clusters privés)
Multi-profils, multi-usages
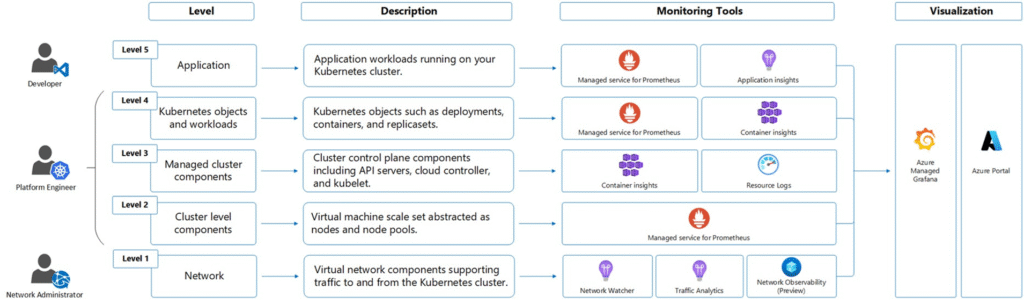
La force de cette vision, c’est qu’elle adresse différents métiers :
- Les Ops y trouvent des métriques système et des alertes
- Les Devs peuvent brancher leurs applications à Application Insights
- Les analystes peuvent croiser des métriques business et techniques
- Les équipes sécurité peuvent faire du threat hunting avec les logs
📌 Les traces, via Application Insights, nécessitent une instrumentation manuelle par SDK selon le langage (Java, .NET, Python…).
C’est rarement fait au début, mais fortement recommandé sur le long terme.
Observabilité réseau
Microsoft propose aujourd’hui deux approches réseau :
| Outil | Portée |
|---|---|
| Traffic Analytics | Niveau Azure / VNet |
| Retina (en preview) | Niveau cluster, via eBPF |
🧪 Retina est un projet open source lancé par Microsoft (KubeCon 2024), mais :
- Encore jeune
- Assez lourd à opérer (logs + CPU)
- Et coûteux à grande échelle
💡 Si besoin de visibilité réseau intra-cluster (pods ↔︎ pods), des alternatives comme Hubble + Cilium existent, mais demandent une souscription (~350€/mois/cluster). À ce jour, non recommandé dans un contexte standard AKS
Azure Monitor Workspace (Prometheus)
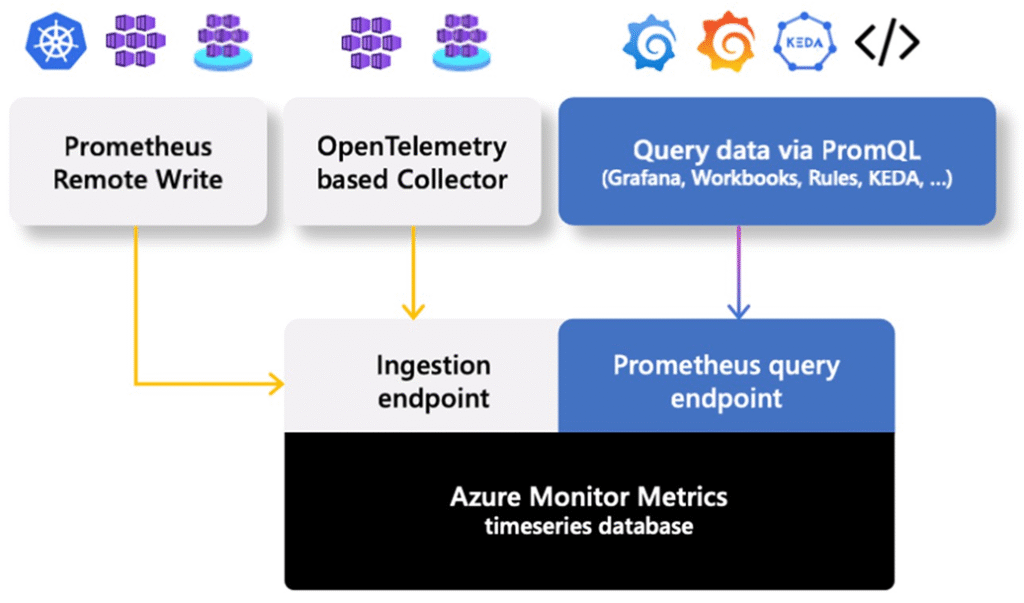
Jusqu’à récemment, intégrer Prometheus dans Azure voulait dire maintenir soi-même l’outil (service, base de données, stockage…).
Microsoft propose désormais une alternative PaaS : Azure Monitor Workspace, qui expose une expérience Prometheus managée, sans avoir à installer Prometheus dans tes clusters.
🧩 Concrètement :
- C’est Microsoft qui héberge, met à jour et sécurise le backend Prometheus
- Tu ne paies que la consommation réelle
- Et tu restes 100% compatible PromQL, ce qui permet de migrer des dashboards existants sans modification
Ce service est invisible côté Kubernetes : les clusters AKS (ou même on-prem) envoient leurs métriques via scraping, et Prometheus les traite côté Azure.
📌 Pour que ça fonctionne, tu dois configurer le scraping sur trois niveaux :
- Le cluster Kubernetes (via les Diagnostic Settings)
- Les nœuds (via kubelet et Node Exporter)
- Les applications, via des annotations Prometheus et/ou des agents OpenTelemetry
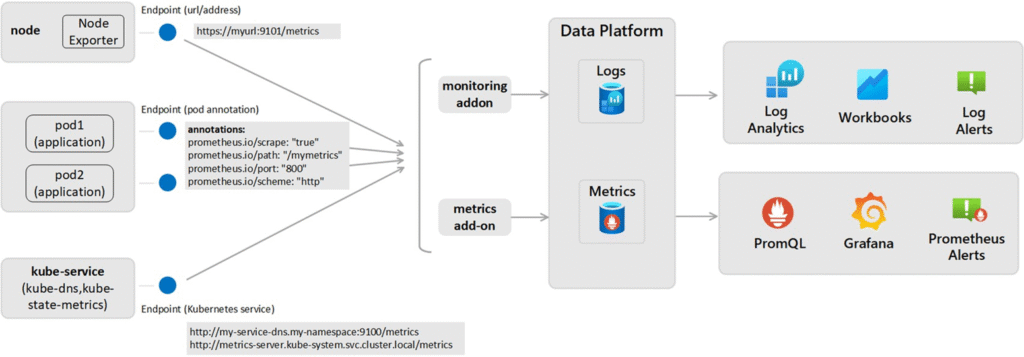
💡 Et côté app, il faudra aussi que les développeurs :
- Exposent les métriques avec le bon endpoint (
/metrics) - Documentent ce qu’ils publient
- Et ajoutent les annotations nécessaires dans les manifests YAML
Azure Managed Grafana
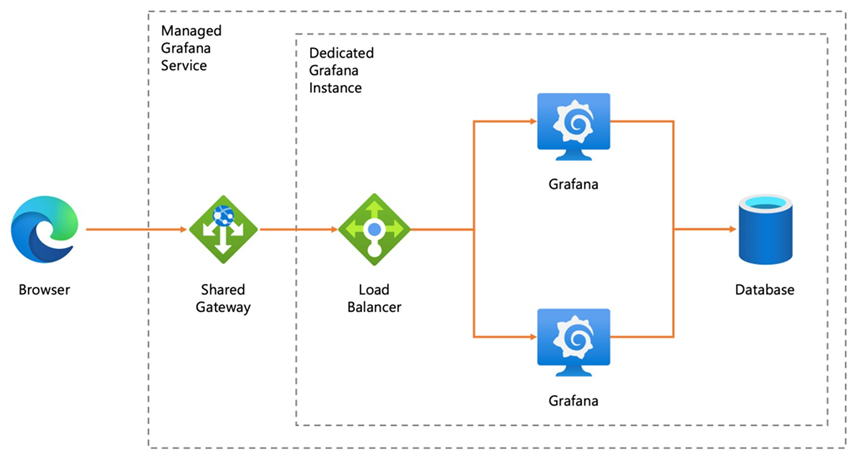
Microsoft a signé un partenariat avec Grafana Labs pour proposer Grafana managé directement dans Azure, sans VM, sans maintenance.
🎯 Objectif : une expérience Grafana intégrée à Azure, avec :
- SSO via Azure AD (Entra ID)
- Private Endpoint natif
- Datasources préconnectées (Azure Monitor, Prometheus, Log Analytics, etc.)
- Sync automatique des équipes via Azure AD
💬 Tu accèdes à l’interface, tu choisis “connecter une datasource Azure” → c’est déjà configuré.
Mais attention : la version managée n’est pas Grafana Enterprise.
Certaines fonctionnalités ne sont pas incluses, notamment :
- Le support des plugins communautaires
- L’extension native Application Insights pour les traces
- Les alertes avancées ou RBAC personnalisés
📎 Pour aller plus loin, il est possible de basculer vers Grafana Cloud (SaaS Enterprise), mais ce n’est plus hébergé chez Microsoft, ce qui pose des enjeux de conformité (notamment en banque ou dans le secteur public)
| ⚠️ Si tu as beaucoup d’utilisateurs potentiels, même inactifs la plupart du temps, cette approche peut vite devenir plus chère qu’une VM auto-hébergée avec Grafana OSS |
Azure Diagnostic Settings
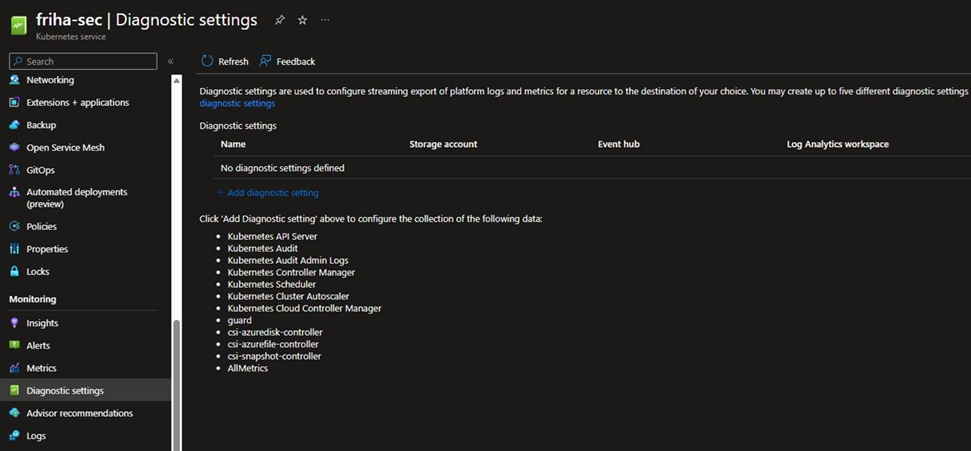
Par défaut, AKS est extrêmement bavard.
Et chaque composant du Control Plane (API Server, Scheduler, ETCD…) peut générer des gigaoctets de logs par jour.
🎯 Moralité : activer les Diagnostic Settings sans filtre, c’est courir à la ruine.
Pour pallier ça, Microsoft propose désormais un profil intelligent :
✅ Minimal Ingestion Profile
C’est une configuration recommandée qui :
- Ne collecte que les logs critiques :
kube-apiserveretetcd - Évite d’enregistrer
kube-audit, extrêmement verbeux (jusqu’à 1 To/mois sur un cluster très actif) - Permet d’avoir de la visibilité sans exploser la facture
À appliquer dès l’instanciation de ton cluster AKS, via Terraform ou ARM.
Synthèse Microsoft
| Élément | Rôle | Notes |
|---|---|---|
| Azure Monitor Workspace | Backend Prometheus managé | Compatible PromQL |
| Container Insights | Collecte de logs + métriques (via DaemonSet) | Prêt à l’emploi |
| Application Insights | Traces applicatives (instrumentation requise) | Devs only |
| Azure Managed Grafana | Visualisation intégrée + SSO | Plugins limités |
| Diagnostic Settings | Active la collecte sur tous composants Azure | À filtrer avec précaution |
5. OBSERVABILITÉ –> VISION SELF-MANAGED
Envie de rester maître de ta stack d’observabilité ?
De tout piloter toi-même, du déploiement aux dashboards, sans passer par les outils managés Azure ?
➡️ le modèle self-managed devient une évidence.
Une stack 100% open source, 100% maîtrisée
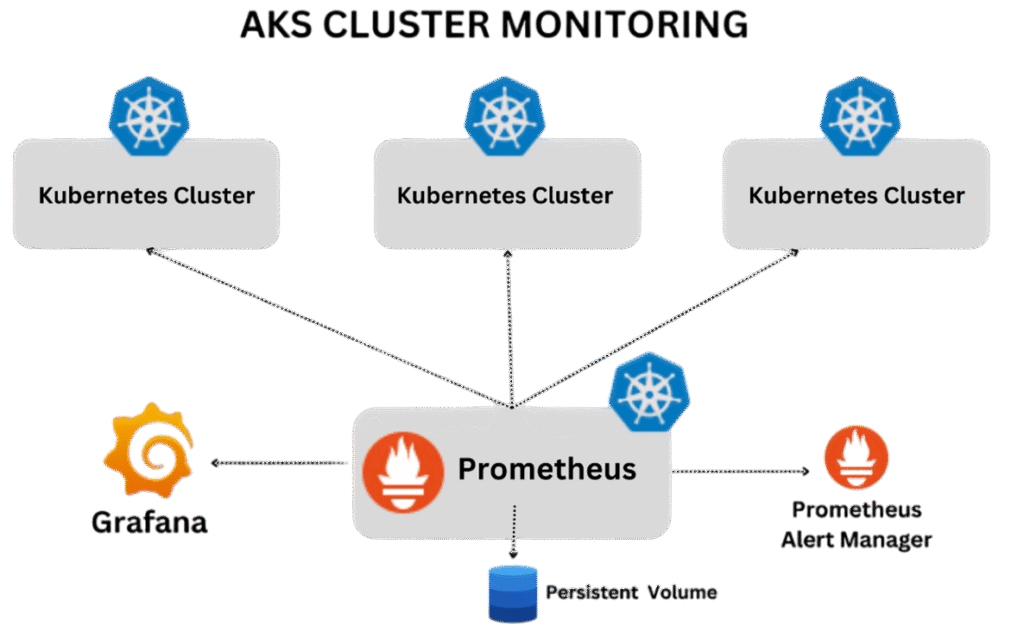
La stack la plus répandue reste :
- Prometheus : pour collecter les métriques
- Grafana : pour visualiser et explorer
- Loki : pour centraliser les logs Kubernetes
Ce trio, proposé et maintenu par Grafana Labs, peut être :
- déployé manuellement en YAML,
- ou plus intelligemment via Helm charts comme
kube-prometheus-stacketloki-stack.
👉 Helm, c’est le Terraform de Kubernetes : un gestionnaire de templates YAML. Tu déclares les valeurs, il génère toute l’archi
helm install monitoring prometheus-community/kube-prometheus-stack
helm install logs grafana/loki-stack
🎯 Résultat : tu déploies une stack complète (Prometheus + Alertmanager + Grafana + Loki) en quelques minutes.
Loki : le Prometheus des logs
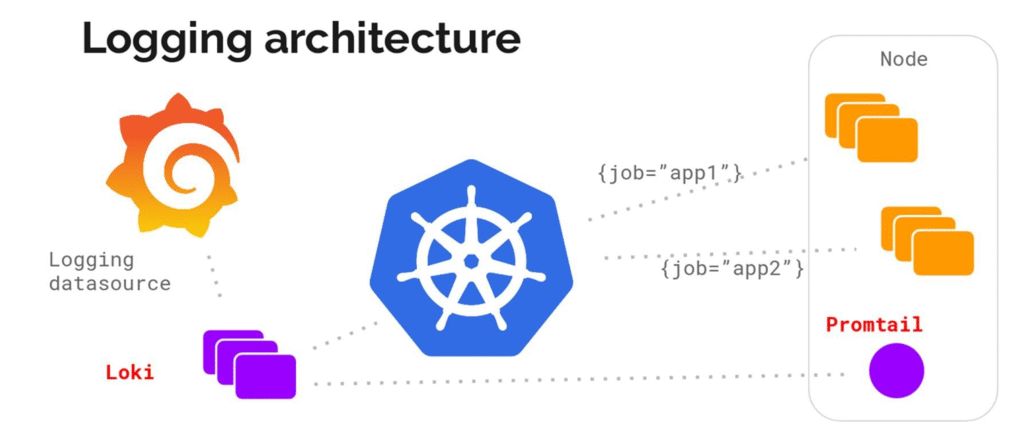
Loki a été pensé pour les logs comme Prometheus l’est pour les métriques :
- Indexation minimale (basée sur labels, pas sur le contenu)
- Compression optimisée
- Intégration native avec Grafana (même requêtage, mêmes dashboards)
- Support du format standard
promtail,fluentbitoulogstash
👉 Loki n’est pas juste une alternative à ELK. C’est la solution log-native Kubernetes, pensée pour la scalabilité.
Mais ça a un prix : la maintenance
Choisir une stack self-managed, c’est assumer :
- Le déploiement initial
- La mise à jour continue (version des charts, compatibilité AKS…)
- La gestion de la résilience (PVC, réplication, sauvegarde, monitoring du monitoring)
Et surtout :
- Chaque composant (Prometheus, Grafana, Alertmanager, Loki…) doit être monitoré lui-même.
- Certaines mises à jour de Kubernetes (notamment depuis la v1.27+) peuvent bloquer si un composant est incompatible avec la nouvelle version.
| ⚠️ Kubernetes bloque désormais un upgrade si des composants comme Prometheus sont en version obsolète Tu dois donc mettre à jour ta stack de monitoring avant de mettre à jour le cluster lui-même |
Et en cas de crash ?
Si ton cluster AKS héberge :
- Ton Prometheus
- Tes dashboards Grafana
- Ton stack Loki…
Alors tu perds tout ton historique en cas d’incident.
➡️ D’où l’intérêt de dissocier les clusters de supervision des clusters applicatifs, ou de sauvegarder régulièrement les volumes et la configuration (ConfigMap, PVC, secrets…).
Exporters, configmaps et alerting
Ta stack Prometheus aura besoin :
- De Prometheus Exporters sur chaque cluster (ex: kube-state-metrics, node-exporter)
- D’une ConfigMap centrale pour la configuration de scrape jobs
- D’Alertmanager pour déclencher des alertes vers Slack, Teams, e-mails, etc.
💡 Ces composants tournent généralement en DaemonSet sur chaque node → ils consomment CPU & RAM, donc à prendre en compte dans la capacité globale du cluster.
Self-managed : gain d’autonomie, coût caché
Avantages :
- Flexibilité totale
- Coût fixe (pas de licence)
- Déploiement cross-cloud / on-prem
- Stack modulaire à la carte
Inconvénients :
- Maintenance manuelle
- À surveiller lors des upgrades K8s
- Risque de perte en cas de crash du cluster
PROCHAIN ARTICLE
Tu as maintenant une boîte à outils claire, pensée pour le terrain, et capable de sécuriser l’exploitation au La continuité, ce n’est pas une option.
C’est ce qui permet à ton cluster de tenir… même quand tout bouge autour.
👉Prochaine étape ?
Faire durer
On parlera mises à jour, résilience, sauvegardes , bref tout ce qu’il faut pour garder ton AKS solide dans le temps
📎 Pour aller plus loin (docs Microsoft) :
- AKS GitOps avec Flux (Microsoft)
- Extension GitOps AKS
- ArgoCD – Documentation officielle
- Surveillance AKS avec Azure Monitor
- Container Insights (overview)
- Azure Managed Prometheus (Preview)
- Azure Managed Grafana
- Helm Chart – kube-prometheus-stack
- Grafana Loki – Projet officiel
- OpenTelemetry – Collecte unifiée
- Kustomize vs Helm



