
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. PROBLÉMATIQUE
Une image bien construite, c’est bien.
Mais une fois qu’elle tourne dans le cluster, tout change.
C’est là que les comportements réels s’expriment.
C’est là que les attaques ont lieu.
Et c’est là que l’infrastructure joue son rôle critique.
Dans Kubernetes, l’exécution repose sur un empilement de couches techniques :
- Des nœuds (VMs) dont vous êtes responsables dans AKS
- Des workloads partagés entre plusieurs équipes
- Des flux réseau qui s’ouvrent et se ferment à chaque déploiement
- Des pods qui communiquent ou pas
➡️ Le risque ici, c’est de penser que le runtime est « géré par AKS ».
Mais dans le modèle de responsabilité partagée, tout ce qui tourne dans les nœuds reste à ta charge : patchs, durcissement, visibilité, détection
Cette 2e partie va donc s’attaquer à la sécurisation de ce qui tourne vraiment dans AKS :
- Depuis le socle OS jusqu’aux pods,
- Depuis le réseau Azure jusqu’aux signaux système captés par eBPF,
- Depuis les workloads critiques jusqu’aux alertes automatisées.
4. PÉRIMÈTRES DE SÉCURITÉ
4.3 Sécurité des Nœuds
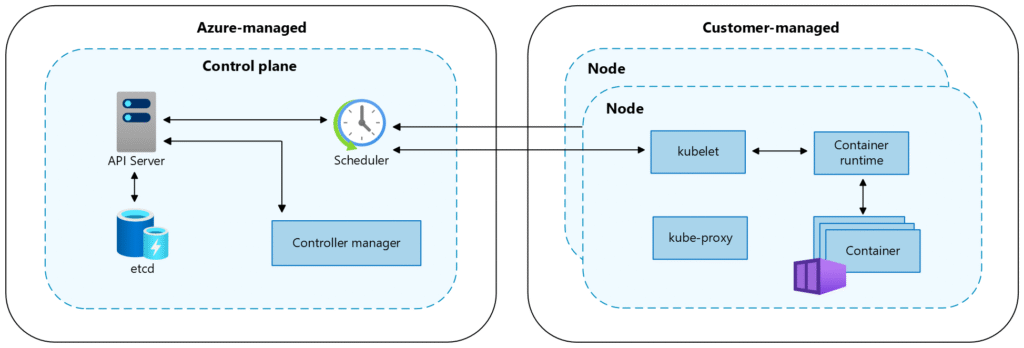
Configuration des Pools de Nœuds
Dans Kubernetes, la sécurité des workloads commence à l’endroit même où ils s’exécutent : les nœuds du cluster. Et contrairement au Control Plane managé par Azure, le Worker Plane
les machines virtuelles qui hébergent les pods reste sous votre responsabilité. C’est l’illustration parfaite du modèle de responsabilité partagée
Mais ces nœuds sont bien plus que de simples hôtes : ils incarnent la surface d’attaque principale du cluster
Une faille non corrigée dans le noyau, une configuration permissive au niveau du système ou un accès SSH mal maîtrisé… et c’est l’ensemble du workload qui est vulnérable
Choisir une base système fiable, supportée, à jour
AKS propose nativement l’OS Ubuntu 22.04 LTS pour ses nœuds. Ce choix présente plusieurs avantages :
- Stabilité : support de long terme assuré par Canonical,
- Intégration Azure : compatibilité immédiate avec les services AKS (monitoring, CNI, autoscaler…),
- Mise à jour fréquente : images AKS actualisées régulièrement sur le Marketplace Azure.
👉 Lorsqu’un cluster est créé ou qu’un scale set est redéployé, les nœuds sont provisionnés avec l’image la plus récente disponible.
Et en post déploiement ?
En environnement de développement, les clusters AKS peuvent être stoppés/restartés à volonté.
Chaque redémarrage recharge l’image de base, et donc les dernières mises à jour système. Mais pour les environnements de production qui tournent 24h/24, la situation est différente.
➡️ Il faut assurer la continuité des patchs de sécurité, y compris ceux qui nécessitent un redémarrage.
C’est ici que l’outil Kured (Kubernetes Reboot Daemon) prend tout son sens :
- Il détecte automatiquement la présence du fichier
/var/run/reboot-required - Il orchestre un redémarrage du nœud de manière maîtrisée : cordon, drain, respect du disruption budget, et relance post-reboot
Résultat : les nœuds restent patchés sans intervention manuelle, ni indisponibilité mal gérée.
Gérer les accès directs : nécessaire, mais encadré
En théorie, aucun accès SSH aux nœuds ne devrait être nécessaire. Kubernetes est conçu pour l’abstraction, l’automatisation et l’orchestration sans login.
Mais en pratique, certains cas le justifient :
- Débogage urgent d’un nœud défaillant,
- Investigation sur une panne critique,
- Exécution d’un correctif hors pipeline.
➡️ Pour ces cas rares, l’accès doit être maîtrisé, éphémère, et traçable :
- Les clés SSH sont générées automatiquement lors du déploiement et stockées dans Azure Key Vault
- Elles ne sont jamais connues ni stockées localement par défaut
- Leur récupération passe par une authentification Azure RBAC stricte
Chaque environnement (dev, staging, prod) dispose de son propre Key Vault, renforçant la séparation de contexte et minimisant les risques d’erreur humaine
| 🧠 Philosophie : “On ne se connecte pas aux nœuds. Et quand on le fait, on sait quand, pourquoi, et avec quelle clé” |
Isolation du Calcul
Dans Kubernetes, la promesse d’abstraction masque parfois une réalité physique : tous les pods tournent sur des nœuds réels, souvent partagés. Et ce partage induit un risque : celui d’un conteneur malveillant ou compromis, capable d’échapper à sa sandbox et d’impacter d’autres workloads.
Dès lors, une question s’impose : jusqu’où faut-il aller pour isoler les charges de calcul ?
Isolation logique
Avant d’envisager des mécanismes d’isolation lourds ou matériels, il faut s’assurer que les fondamentaux sont bien en place :
- Namespaces dédiés par application ou par domaine fonctionnel
- RBAC finement configuré, pour que chaque workload n’accède qu’à ses ressources
- Network Policies pour cloisonner la communication inter-pods
- Et des taints & tolerations pour réserver certains nœuds à des workloads sensibles
✅ Ces mesures sont déjà très efficaces dans 80 % des cas d’usage AKS.
Isolation forte : quand la logique ne suffit plus
Pour les applications critiques, exposées, ou réglementées, une isolation plus stricte peut être envisagée. Plusieurs technologies ont émergé, mais leur maturité reste contrastée :
1.Kernel Isolated Containers (KIC) via Kata Containers
Le principe est d’encapsuler chaque pod dans une micro-VM indépendante, séparée du noyau hôte
- 🟢 Avantage : barrière nette entre les workloads, limite les attaques par évasion.
- 🔴 Limites : impact sur la performance (latence, CPU), incompatibilités avec Azure CNI, CSI Driver Key Vault, etc.
Cas d’usage : charge sensible, traitement de données confidentielles, sandbox d’exécution.
2.Confidential Containers (AMD SEV, Intel TDX)
Basés sur des extensions matérielles, ils créent des enclaves sécurisées où même l’hyperviseur ne peut accéder aux données en exécution.
- 🟢 Sécurité maximale en mémoire
- 🔴 Prérequis : types de VM spécifiques, non compatibles avec toutes les fonctionnalités AKS, encore peu intégrés.
Cas d’usage : workloads réglementés (santé, défense), exigences de souveraineté extrême.
3.Pod Sandboxing (gVisor, Kata, etc.)
Encapsulation des pods dans des runtimes alternatifs pour limiter leur visibilité sur l’OS hôte.
- 🔴 Encore expérimental sur AKS,
- 🔴 Problèmes de compatibilité (monitoring, logs, CSI…),
- 🟢 Intéressant en lab ou R&D, mais pas recommandé en production.
Isolation Réseau
Dans Kubernetes, le réseau est à la fois un levier de performance et un vecteur d’attaque. Et c’est encore plus vrai dans AKS, où la sécurité ne s’arrête pas aux limites du cluster : elle commence dans l’infrastructure Azure elle-même.
👉 Protéger les nœuds, c’est donc contrôler ce qui entre et ce qui sort, depuis la couche réseau du cloud jusqu’aux pods.
Des nœuds cloisonnés dans un VNet dédié
La première brique, c’est l’isolation réseau au niveau du Virtual Network :
- Aucun autre composant (VM, App Service, Bastion…) ne partage ce reseau
- Cela simplifie le filtrage, le monitoring et réduit le risque de latéralisation en cas de compromission.
Azure Firewall
Tout le trafic sortant est redirigé vers un Azure Firewall central, positionné dans une architecture Hub & Spoke :
- Contrôle des flux sortants (ex : Ubuntu, NGINX, GitHub),
- Vérification des flux entrants (API exposées, services inter-VNet),
- Journalisation complète des accès autorisés et bloqués,
- Règles centralisées au niveau d’un seul composant.
| ⚠️ Cette redirection via table de routage UDR est obligatoire, même pour Internet, afin d’éviter tout routage asymétrique (flux retour non maîtrisé) |
NSG + Flow Logs
Chaque Subnet AKS est associé à un NSG (Network Security Group).
Mais contrairement à une utilisation classique, ici :
- Les règles sont volontairement ouvertes ou pas
- L’accent est mis sur l’observabilité, pas sur le blocage
Pourquoi ? Car ce sont les VNet Flow Logs qui font le travail :
- Collecte de tous les flux (IP source, IP destination, protocole, port)
- Transfert vers Traffic Analytics pour analyse consolidée
- Identification des schémas anormaux, exfiltrations, connexions inattendues
❇️ Bonus : coût très faible et déploiement simple, même sur des clusters très actifs.
Et l’observabilité intra-cluster ?
Certains outils (comme Cilium, Calico Enterprise) permettent de superviser les flux entre pods à l’intérieur du cluster.
Mais dans mon cas, cette granularité est jugée :
- Trop coûteuse à maintenir
- Difficile à industrialiser
- Et redondante avec les contrôles déjà en place (Network Policies, RBAC, audit logs…)
👉 le mieux c’est de se concentrer sur les échanges entre le cluster et le reste du monde, tout en renforçant les frontières internes par la logique Kubernetes
Une architecture prête pour demain
Enfin, ce modèle réseau s’appuie déjà sur les bonnes pratiques à venir :
- VNet Flow Logs remplace progressivement les NSG Flow Logs,
- Azure Monitor Network Insights unifie la vision des flux à l’échelle du tenant
4.4 Sécurité des Applications
On a parlé des nœuds, de l’OS, du réseau. Mais soyons honnêtes :
Ce qui attire vraiment l’attention des attaquants, ce n’est pas l’infrastructure…
… ce sont les applications elles-mêmes
Les pods, les services exposés, les API, les ConfigMaps, les secrets en clair — bref, tout ce qui tourne à l’intérieur du cluster
Et c’est là que la sécurité devient vraiment complexe.
Parce que les applications changent vite : chaque commit, chaque livraison, chaque test Dev peut introduire une nouvelle faille, une exposition involontaire, ou contourner une politique sans le vouloir.
➡️ C’est exactement pour ça que Microsoft Defender for Containers est un incontournable dans AKS
Pas parce qu’il “fait plus”, mais parce qu’il voit ce que les règles statiques ne peuvent pas prévoir :
ce qui se passe en temps réel, à l’intérieur des workloads
Un déploiement fluide, sans friction
L’un des gros avantages de Defender, c’est son simplicité de mise en œuvre :
- 🟢 Activation au niveau de la souscription
- 🟢 Application automatique à tous les clusters AKS (existants ou futurs)
- 🟢 Sans agent à ajouter dans les images
- 🟢 Facturation proportionnelle au nombre de nœuds (VMSS), donc prévisible
Une posture de sécurité visible, lisible, actionnable
Dès l’activation, Defender analyse en continu la configuration de ton cluster :
- Pods avec
allowPrivilegeEscalation: true - Conteneurs tournant en
root - Ports exposés en clair
- Absence de Network Policies
- ConfigMaps contenant des secrets non chiffrés…
Et tout ça remonte dans Defender for Cloud, avec :
- Un score de sécurité global
- Des recommandations actionnables
- Une traçabilité claire (idéal pour SecOps ou la compliance)
Tu n’as pas besoin d’être expert Kubernetes pour comprendre ce qui cloche
Vulnérabilités : analyse continue, sans agent, sans friction
Deuxième force de Defender : l’analyse des vulnérabilités dans les pods déployés
Et là encore, aucun agent à embarquer, aucun changement dans les pipelines.
Comment ça fonctionne ?
- 🟢 Les images sont scannées à l’import ou à la mise à jour dans ACR,
- 🟢 Les pods en cours d’exécution sont identifiés via l’API AKS,
- 🟢 Les alertes sont enrichies avec : le CVE, l’image, le namespace, le digest, etc.
🎯 Résultat : tu ne reçois pas juste une alerte.
Tu sais où elle s’exécute, ce qu’il faut corriger, et avec quelle priorité.
Runtime : observer le comportement réel avec eBPF
Troisième brique : la surveillance du runtime, grâce à un DaemonSet basé sur eBPF.
➡️ eBPF permet d’observer le trafic réseau, les appels système et les comportements suspects, sans impacter les performances.
Ce que Defender peut voir en profondeur :
- Tentatives d’escalade de privilèges (
setuid,ptrace, etc.) - Création de processus ou fichiers anormaux
- Accès à des chemins critiques (
/etc/passwd,/var/run/secrets, …) - Connexions réseau vers des IP douteuses
Et bien sûr, tout cela peut être :
- Corrélé automatiquement dans Microsoft Sentinel
- Exporté vers un SIEM via connecteurs natifs Azure
Tu ne reçois plus des alertes “brutes”, mais des événements contextualisés, prêts à être traités dans un playbook automatisé
Une sécurité étendue à tout l’écosystème Azure
Defender for Containers n’est pas limité à AKS.
Il s’appuie sur Defender Vulnerability Management pour élargir ta vision à tout Azure :
- VMs, App Services, Storage
- Corrélation entre vulnérabilités et ressources critiques
- Aide à la priorisation basée sur le risque métier, pas juste le score CVSS
Tu gagnes une vision holistique, qui ne s’arrête pas au pod mais couvre toute la chaîne de valeur applicative.
Ce qu’il faudra mettre en place concrètement
| Objectif | Ce que Defender for Containers apporte |
|---|---|
| Visibilité sur la configuration des pods | Posture de sécurité continue dans Defender for Cloud |
| Scan des images sans effort | Analyse à l’import dans ACR + corrélation avec les pods actifs |
| Surveillance en runtime | Détection eBPF sur les comportements anormaux en profondeur |
| Intégration dans le SIEM/SOC | Corrélation automatique avec Sentinel ou autre SIEM via connecteurs |
| Vision transverse de la sécurité | Défense intégrée à toute la surface Azure (pas juste AKS) |
Ce qu’il faut retenir
- Sécuriser les nœuds, c’est sécuriser les fondations
Le choix d’un OS fiable (comme Ubuntu LTS), l’automatisation des patchs via Kured, et l’encadrement strict des accès directs (avec Key Vault et Azure RBAC) garantissent un socle stable et maîtrisé pour les workloads AKS - L’isolation des workloads est une stratégie graduée
Kubernetes propose nativement des garde-fous efficaces (RBAC, namespaces, Network Policies).
Les mécanismes d’isolation renforcée (Kata Containers, Confidential VMs) sont puissants, mais encore complexes à industrialiser. Le bon compromis dépend du niveau de risque, des contraintes métiers, et de la maturité des équipes. - La sécurité réseau commence hors du cluster
En AKS, une architecture réseau bien pensée repose sur quatre piliers :- VNet dédié
- Azure Firewall en sortie
- NSG en mode observabilité
- Logs centralisés via Flow Logs
Cette approche offre une visibilité claire, sans lourdeur opérationnelle, tout en restant évolutive
- La sécurité applicative passe par la visibilité runtime
Defender for Containers détecte ce qu’aucune politique statique ne peut prévoir :- Les vulnérabilités dans les images
- Les configurations risquées dans les pods
- Les comportements suspects à l’exécution (grâce à eBPF)
PROCHAIN ARTICLE
Dans la 3ᵉ et dernière partie, on ira plus loin sur un aspect souvent négligé :
la gouvernance de la sécurité dans AKS.
On parlera de secrets gérés proprement avec Azure Key Vault,
de politiques qui s’imposent toutes seules (OPA, Kyverno, Azure Policy),
et de conformité automatique, sans tableau Excel.
Le tout, toujours ancré dans des cas concrets pas du théorique
📎 Pour aller plus loin (docs Microsoft) :
- Sécuriser les nœuds AKS
- Kured – Redémarrage automatique sécurisé
- Azure Firewall – Documentation
- Network Policies sur AKS
- Flow Logs Azure
- Defender for Containers – Vue d’ensemble
- eBPF dans Defender AKS



