
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. PROBLÉMATIQUE
🎯 Dans AKS, tout le monde parle de scalabilité et de résilience… mais personne ne parle vraiment de sauvegarde.
Et pourtant, c’est souvent là que tout se joue.
Le jour où ton cluster tombe, où un secret est supprimé par erreur, où un volume persistant se corrompt, ou où un upgrade casse un composant essentiel… ce n’est pas ton autoscaler qui va te sauver.
👉 La seule chose qui fera la différence, c’est ta stratégie de sauvegarde et de restauration.
Le problème ?
AKS ne se sauvegarde pas en un clic
Il n’y a pas un bouton magique Restore my cluster
Tu dois gérer trois couches différentes, chacune critique :
1️⃣ L’infrastructure (IaC) → ce qui définit ton cluster
2️⃣ L’état du Control Plane (etcd) → ce qui fait tourner Kubernetes
3️⃣ Les données persistantes (PVC, disques, fichiers) → ce que ton business ne peut pas perdre
Et le piège, c’est de croire que ton repo Git suffit.
Ou que reconstruire un cluster “from scratch” est simple.
Ou encore que Azure Backup protège automatiquement tout l’écosystème.
🛑 Faux. Et dangereux
Une erreur YAML, un secret écrasé, un storage class supprimé, un PV corrompu…
Et c’est parfois des heures de downtime, voire une perte définitive.
La réalité est simple :
✔ Sauvegarder, c’est prévoir
✔ Restaurer, c’est maîtriser
❌ Et sans tests réguliers, ton plan DR n’est qu’un document PDF dans un SharePoint
3. BACKUP
Sauvegarde de l’infrastructure AKS (IaC)
Dans l’univers AKS, la sauvegarde ne commence pas par un snapshot disque.
Elle commence bien avant, dans Git, là où tu déclares ton cluster.
L’infrastructure AKS est décrite dans le code
AKS étant un service managé, l’infrastructure du cluster (Node Pools, VNet, Add-ons, RBAC…) est généralement définie en Infrastructure as Code (IaC) avec Terraform, Bicep ou ARM.
Ce code est versionné dans un repo Git, avec :
- Une stratégie de tag (par exemple
v1.4.2,prod-2025-11) - Un historique clair de chaque modification
- Une traçabilité complète des déploiements réalisés
💡 En cas d’incident critique, c’est cette IaC qui te permet de recréer un cluster à l’identique, avec exactement les mêmes paramètres, la même configuration réseau, et les mêmes add-ons activés.
Ne pas confondre Git et dernière version en prod
Un piège courant serait de considérer le dernier commit comme la version en production.
| ⚠️ Mauvaise idée Tu dois pouvoir dire : –> “Le cluster aks-prod déployé le 17 Novembre 2025 correspond exactement au tag release-v1.3.5.” |
Et pour ça, tu dois :
- Taguer chaque release de ton code IaC dans Git
- Marquer le cluster avec ce tag (
git_tag=release-v1.3.5) via un label ou un tag Azure - Conserver les pipelines utilisés pour ce tag (dans Azure DevOps, GitHub Actions, etc.)
Résultat ?
👉 Tu peux restaurer l’infra d’un cluster tombé sans tâtonner : même version, même configuration, même résultat
Sauvegarde de l’état du cluster Kubernetes
Tu penses que tout est dans les YAML ?
🛑 Faux
Le cœur vivant de ton cluster, c’est etcd.
ETCD : la mémoire du Control Plane
etcd, c’est une base de données clé-valeur distribuée, hautement disponible, et critique.
C’est elle qui stocke :
- La configuration complète de ton cluster
- Les certificats internes
- Les rôles RBAC et les bindings
- Tous les objets Kubernetes : Deployments, Services, ConfigMaps, Pods, etc.
- Et si tu n’as rien externalisé : tous les secrets de ton application
Oui, Microsoft garantit sa haute dispo
Mais toi, tu dois penser à autre chose :
Et si c’est moi qui casse quelque chose ?
(un kubectl apply trop rapide, une suppression de secret par erreur…)
Dans ce cas, deux options :
- Tu redéploies le bon YAML et tu corriges.
- Ou tu restaures un snapshot de l’état précédent. Et pour ça, il faut avoir sauvegardé etcd au préalable.
Outils de sauvegarde d’état
Plusieurs outils permettent de faire une sauvegarde cohérente de l’état Kubernetes :
- Velero : open source, leader dans ce domaine.
- Kasten K10 (par Veeam) : version commerciale avancée.
Ils permettent :
- D’exporter et restaurer des objets Kubernetes
- De snapshotter etcd, avec les RBAC, les Secrets, les ConfigMaps, etc.
- De restaurer rapidement un namespace ou un cluster entier
🧠 Astuce : pense à exporter régulièrement la configuration critique, même dans un cluster « infra as code », car l’état runtime (ex : un secret modifié via kubectl) n’est pas toujours versionné dans Git. |
Sauvegarde des objets stateful (Volumes persistants)
Kubernetes, ce n’est pas que de l’éphémère.
Dès que tu déploies une base PostgreSQL, un Redis, un stockage d’assets…
➡️ Tu passes dans le monde des Persistent Volume Claims (PVC).
Où sont stockés tes volumes ?
Dans AKS, les PVC sont automatiquement provisionnés sur :
- Des Azure Disks (généralement Premium ou Ephemeral)
- Des Azure Files
- Ou des solutions tierces comme Azure NetApp Files ou Azure SAN Preview
Le tout est orchestré par des StorageClasses définies au niveau du cluster.
Snapshots Kubernetes natifs
Bonne nouvelle : Kubernetes permet de gérer des snapshots à la volée via l’API VolumeSnapshot
Ce mécanisme, combiné à Azure Backup ou à Velero, permet de restaurer un état précis d’un volume sans redéployer l’application.
Tu peux ainsi :
- Restaurer un volume suite à une perte de données
- Cloner un environnement à partir d’un snapshot
- Automatiser des sauvegardes régulières via un
CronJobKubernetes
💡 Ma Recommandation :
- Utilise un stockage externe (Blob, File, autre subscription) pour éviter les risques de co-localisation.
- Planifie une sauvegarde régulière des PVC critiques.
- Teste tes restaurations, pas juste tes backups.
Sauvegarde Kubernetes
Dans AKS, la sauvegarde n’est pas un luxe. C’est une stratégie.
Et elle se joue sur deux tableaux :
1. L’état du cluster
Tu peux le reconstruire à partir :
- De snapshots
etcdvia des outils comme Velero - Ou de ton code Infra as Code, versionné et traçable dans Git (IaC + GitOps)
2. Les objets stateful
Tu dois protéger tout ce qui touche à la persistance des données :
- Volumes montés dans tes pods (PVC)
- Disques Azure ou solutions tierces (NetApp, SAN, etc.)
Et Kubernetes a prévu le coup : avec ses API de snapshot, tu peux faire des copies cohérentes des volumes à chaud, voire à fréquence planifiée.
Deux outils de référence
- Velero
Un outil open-source, éprouvé, complet, et largement adopté
- Azure AKS Native Backup
La solution officielle de Microsoft, intégrée dans Azure Backup Center
Azure AKS Native Backup
Quand tu actives AKS Native Backup, tu passes par :
- Un Backup Vault Azure
- Le Backup Center pour orchestrer tes stratégies
- Et un Storage Account pour stocker les snapshots
✅ La bonne nouvelle :
- Compatible avec les clusters AKS privés
- Portée possible au niveau cluster ou par namespace spécifique
Mais maintenant, regarde bien les limites 👇
⚠️ Les points de vigilance
🔴 Tarification par namespace protégé
Mutualisation = coût qui explose vite
🔴 Support limité à certains types de stockage :
- ❌ Pas de support pour Azure Files, BlobFuse, NFS
- ✅ Uniquement les disques Azure Managed Disks via CSI Driver
- ❌ Pas compatible avec Premium SSD v2, ni Ultra Disks
🔴 Pas de restauration inter-régions
Donc pas utilisable pour un plan de reprise (PRA) entre régions.
🔴 Limitation à 1 To par volume
Hors-jeu pour les workloads lourds (big data, bases volumineuses…).
🔴 10 restaurations max par jour
Oui, 10 par jour. Pas plus.
💡 Ma Recommandation :
Azure AKS Native Backup est une solution prometteuse, mais encore en phase de maturation.
Elle peut faire l’affaire sur des environnements simples ou non critiques, mais ne suffit pas à elle seule pour garantir une reprise solide
👉 Pour un plan de continuité sérieux, complète-la avec une solution éprouvée comme Velero, ou Kasten si tu disposes du budget nécessaire
Velero
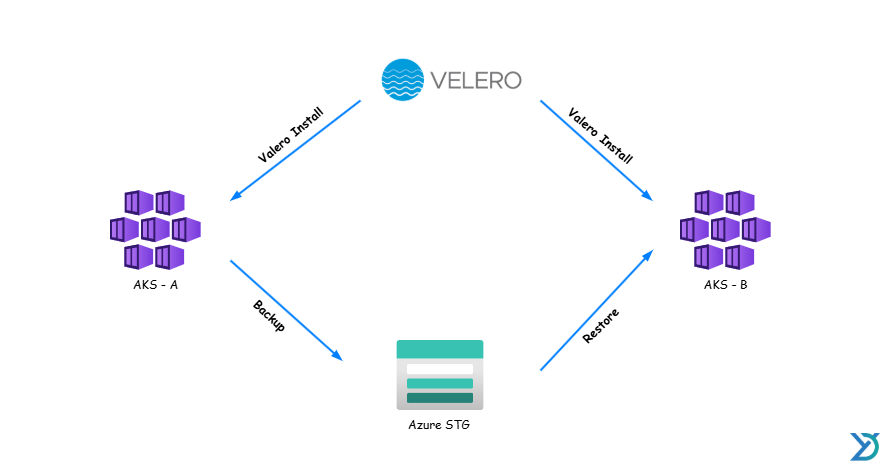
Quand tu veux une vraie solution de sauvegarde Kubernetes, indépendante et souple, Velero arrive en tête de liste.
Pourquoi ? Parce qu’il coche presque toutes les cases , sans se limiter à Azure, sans frais cachés, et sans dépendances complexes.
Présentation de Velero
- 🟢 Open-source, maintenu par VMware, et toujours gratuit.
- 🟢 Cloud-agnostique : tu peux l’utiliser aussi bien sur AKS, EKS, GKE que sur des clusters on-premises.
- 🔵 Grâce à un système de plugins, il s’adapte au provider sous-jacent.
- 🟢 Déploiement simple : installation via Helm Chart, en quelques commandes.
- 🟢 Administration via CLI : pas encore d’interface Azure Portal, mais une CLI très complète.
À quoi sert Velero concrètement ?
- Sauvegarde complète ou partielle de ton cluster (namespaces, ressources, volumes).
- Restauration rapide en cas de défaillance ou de suppression accidentelle.
- Migration de workloads entre clusters (par exemple : d’un cluster AKS de préprod vers un nouveau cluster prod).
💡 Cas typique : tu reconstruis plus vite un cluster depuis une sauvegarde Velero que via un redeploy complet à partir du code Terraform
Industrialisation avec Velero
Ce qui le rend encore plus utile :
- Tu peux orchestrer les sauvegardes dans un Storage Account.
- Et ensuite laisser Azure Backup se charger de protéger ce Storage Account.
🚨 En cas de crash de production
Tu as deux options :
- Mode “urgence” :
Tu relances une restauration directe Velero depuis le Storage Account → rapide, efficace, sans redeployer manuellement tout l’Infra - Mode “plan B” :
Tu repars from scratch via IaC + manifests… mais avec plus de stress, plus de temps, plus de risques.
Bonnes pratiques de restauration
Sauvegarder, c’est bien.
Restaurer sans stress, c’est mieux.
Et ça ne s’improvise pas.
Dans un cluster AKS, la reprise après incident repose sur une préparation continue, une automatisation rigoureuse, et surtout, une mise en situation régulière.
GitOps = DR par le code
Quand ton cluster est décrit intégralement dans Git (via Terraform, Helm, Kustomize…), tu peux :
- Restaurer l’infrastructure AKS à l’identique.
- Rejouer les déploiements applicatifs de façon déterministe.
- Vérifier l’état attendu via des outils comme Flux ou ArgoCD
💡 En combinant GitOps avec des tags ou des releases bien structurées, tu peux reconstituer un cluster à une version précise, sans tâtonner.
Automatiser les restaurations critiques
Une bonne stratégie de DR dans AKS inclut :
- Des scripts prêts à l’emploi pour restaurer etcd ou déclencher une restauration Velero.
- Des snapshots automatisés des volumes persistants (PVC) stockés dans un Storage Account bien identifié.
- Des pipelines CI/CD dédiés aux opérations de reprise : recréer les secrets, réinitialiser les certificats, redéployer les charts Helm, etc.
Tester régulièrement (vraiment)
Un plan DR non testé = un vœu pieux
✅ Intègre un test de restauration trimestriel dans ton runbook opérationnel
Cela peut inclure :
- Un cluster temporaire pour tester la restauration des volumes + manifestes
- Un replay GitOps sur un cluster sandbox
- Des alertes si la durée de restauration dépasse un seuil critique
Objectif : restaurer sans improviser
En cas de crash ou de mauvaise manip :
- Tu sais quoi relancer.
- Tu as les artefacts nécessaires.
- Tu valides que la reprise respecte les SLA métiers.
| 💡 Et surtout : Tu évites les 10 heures de stress pour reconstituer ce que tu aurais pu restaurer en 10 minutes. |
7. EN CONCLUSION
AKS, c’est pas juste un bouton “Deploy” ! Faut penser upgrades, scalabilité, backups… tout dès le début
Pas de résilience sans un bon design ! Un énorme merci d’avoir suivi cette série AKS 🙌🚀 !
📎 Pour aller plus loin (docs Microsoft & GitHub)
• AKS – Sauvegarde & restauration :
https://learn.microsoft.com/azure/aks/backup-restore-overview
• Azure AKS Native Backup (Backup Center + Backup Vault) :
https://learn.microsoft.com/azure/backup/azure-kubernetes-service-backup-overview
• Azure Backup pour Managed Disks :
https://learn.microsoft.com/azure/backup/backup-managed-disks
• VolumeSnapshot Kubernetes + CSI (Azure Disks) :
https://learn.microsoft.com/azure/aks/csi-storage-snapshots
• Azure Files – limitations & scénarios (si utilisé pour les PVC) :
https://learn.microsoft.com/azure/storage/files/storage-files-introduction
• Azure NetApp Files (si cluster stateful) :
https://learn.microsoft.com/azure/azure-netapp-files/
🟣 Kubernetes (upstream) => API & concepts
• etcd => documentation officielle :
https://etcd.io/docs/
• VolumeSnapshot API Kubernetes :
https://kubernetes.io/docs/concepts/storage/volume-snapshots/
• Persistent Volumes (PV) & Persistent Volume Claims (PVC) :
https://kubernetes.io/docs/concepts/storage/persistent-volumes/
🟢 Outils Backup & DR (Open Source & Enterprise)
• Velero (VMware) => Documentation officielle :
https://velero.io/docs
• Velero GitHub (plugins cloud, contributeurs, issues) :
https://github.com/vmware-tanzu/velero
• Kasten K10 (Veeam) => Documentation :
https://docs.kasten.io
🟡 GitOps & IaC pour la continuité d’activité
• Flux GitOps => Documentation officielle :
https://fluxcd.io/docs/
• ArgoCD => Documentation officielle :
https://argo-cd.readthedocs.io
• Terraform AKS => Provider AzureRM :
https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/kubernetes_cluster
• Gestion Git des releases & tags (Git SCM) :
https://git-scm.com/book/en/v2/Git-Basics-Tagging
🔴 Microsoft Architecture Guidance (Business Continuity)
• Azure Well-Architected Framework => Fiabilité :
https://learn.microsoft.com/azure/architecture/framework/resiliency/overview
• DRP / PRA dans Azure (zones, régions, snapshot, backup) :
https://learn.microsoft.com/azure/architecture/resiliency/recovery-deployments
📘 Bonus : bonnes pratiques & retours terrain
• Kubernetes Disaster Recovery Patterns :
https://kubernetes.io/docs/tasks/administer-cluster/disaster-recovery/
• Etcd Disaster Recovery Guide :
https://etcd.io/docs/v3.5/op-guide/recovery/