
1. INTERVENANTS
DJEBBOURI Younes
Architecte Azure et DevOps 🚀💻✨
2. PROBLÉMATIQUE
⛔ Mettre à jour un cluster Kubernetes, ce n’est pas du “next next finish”.
Avec AKS, chaque upgrade ne se limite pas à passer d’une version à une autre de Kubernetes.
C’est tout un écosystème qui bouge : kubelet, kube-proxy, DNS, CNI, CSI, Metrics Server, Secret Provider, autoscaler, etc.
👉 Et parfois, un simple clic sur “Upgrade” peut déclencher des breaking changes invisibles… jusqu’à ce que ton cluster tombe.
Les 3 grandes problématiques
1. Comment faire les mises à niveau sans faire sauter le cluster ?
👉 Cycle de vie Kubernetes → Risques de breaking change, stratégies d’upgrade (canary, blue/green, LTS…)
2. Comment assurer la résilience de l’infrastructure sous-jacente ?
👉 Haute disponibilité → Zones, redondance, autoscaler, Node Auto-Provisioning (NAP), etc
3. Comment garantir la résilience des applications ?
👉 Résilience applicative → HPA, Dapr, probes, tolerations… Les bonnes pratiques doivent être codées dès le départ
3. AKS UPGRADE
Stratégies d’Upgrade AKS
Sur AKS, tu choisis la version de Kubernetes que tu veux utiliser, mais tu dois respecter la logique de progression imposée par Azure :
- 🟢 1.30 vers 1.31
- 🟢 1.32 vers 1.33
- 🔴 1.29 vers 1.32
Tu es donc obligé de passer par chaque version intermédiaire, avec tous les impacts que cela implique.
Cinq approches pour gérer tes upgrades
Stratégie 1 → Mise à jour automatique (Automatic Update)
Laisser AKS faire les mises à jour tout seul ?
Ce n’est pas une option recommandé en prod
Tu ne sais pas quand ça démarre, ni combien de temps ça prendra.
Et le déplacement des workloads peut se faire sans contrôle précis sur la fenêtre d’impact.
⛔ On écarte tout de suite
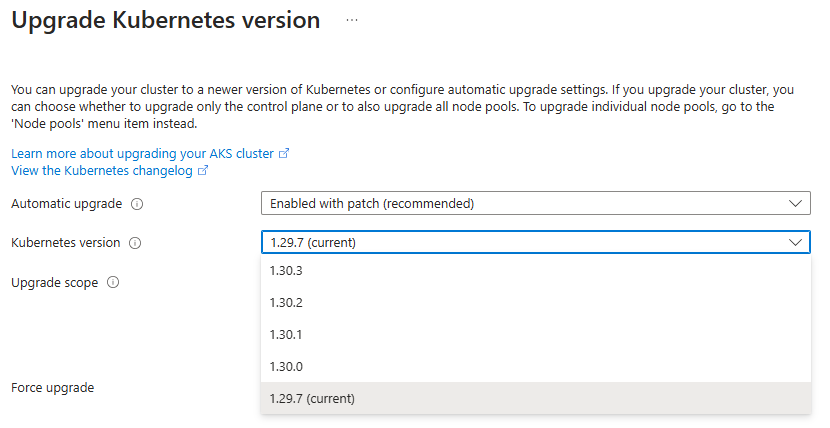
Stratégie 2 → Suivre le rythme des releases Kubernetes
Une mise à jour régulière, version après version.
Tu restes dans la zone de support AKS (N, N-1, N-2), mais…
Tu dois gérer les changements fréquents, les tests, les éventuelles régressions.
Et plus l’environnement est complexe, plus c’est tendu
Stratégie 3 → Faire des sauts de version en chaîne
Tu attends 12 à 18 mois, puis tu fais plusieurs upgrades successives pour rattraper.
Mais ce genre de mise à niveau combinée est plus risquée :
- Tu accumules les breaking changes, et ton rollback devient plus difficile à maîtriser
Stratégie 4 → Upgrade progressif par Node Pool (type Canary)
Tu isoles les workloads dans des Node Pools séparés ( userpool )
et tu mets à jour un Node Pool à la fois.
Tu réduis la surface à risque, tu peux tester avant de généraliser
👉 Et si problème il y a : tu peux toujours recréer un Node Pool avec une version antérieure
Stratégie 5 → Cluster éphémère (Blue/Green)
Tu reconstruis ton cluster dans un environnement parallèle (le « Green« ),
pendant que le « Blue » continue de tourner.
Une fois validé, tu fais basculer la prod vers le Green,
et tu peux désactiver ou supprimer l’ancien.
🟢 Meilleure maîtrise
🟢 Moins d’interruption
| Depuis la version 1.28, bonne nouvelle : ➡️ Les workloads peuvent exprimer une exigence minimale de compatibilité Kubernetes, ce qui permet à AKS de bloquer un upgrade si nécessaire. Et si l’upgrade échoue, AKS peut revenir en arrière automatiquement |
| ✳ Le meilleur choix reste de prévoir le Blue/Green dès l’architecture initiale, via Terraform. Tu gagneras en sécurité, en lisibilité, et en autonomie |
5. RESILIENCE
Quels risques veut-on vraiment adresser ?
Avant d’acheter des options de haute dispo à tout-va, il faut qualifier les types de pannes que tu souhaites absorber, et à quel niveau :
| Risque | Périmètre concerné | Réponse disponible |
|---|---|---|
| Perte d’un Pod | Résilience applicative | Kubernetes recrée automatiquement le Pod sur un autre nœud. |
| Perte d’un nœud | Résilience infrastructure | Un nouveau nœud est provisionné, le défaillant est évacué. |
| Panne régionale Azure | Résilience business | Si anticipée, tu peux redéployer dans une autre région. |
| Panne d’une géographie entière (ex. Western Europe + North Europe) | Résilience stratégique | Demande un plan DRP / Multi-Cloud, souvent lourd à justifier. |
| ⚠️ Important : AKS, c’est juste une brique dans ton système. Si tu as un backend SQL, un cache Redis ou une file d’attente en single-region… c’est probablement eux qui vont plier en premier, pas ton cluster |
Accepter qu’il n’existe pas de “zéro risque”
AKS est un service régional, avec une tolérance aux pannes dans la région.
Mais dès qu’on parle de bascule entre régions (ou géographies Azure), ce n’est plus automatique.
Et là, tout devient plus complexe :
- Bascule de données (et pas juste du code)
- Synchronisation des secrets, certificats, configs
- Réplication entre bases, entre services, entre régions
💸 Et bien sûr, tout ça a un coût :
➡️ Tu veux du chaud-froid (active/passive) ? Double les ressources.
➡️ Tu veux du chaud-chaud ? Prévois aussi la complexité de synchro et de test.
La vraie question devient donc :
👉 “Mon business est-il prêt à financer cette résilience supplémentaire ?”
Résilience Infrastructure
Maîtriser la scalabilité
Tu ne peux pas être résilient si ton cluster n’arrive déjà pas à scaler correctement.
AKS te propose trois stratégies de scalabilité selon le niveau de contrôle que tu veux garder :
1. Manual Scale
- Tu fixes manuellement le nombre de nœuds par pool
- Simple et prévisible
- Mais si ça sature, ça plante.
2. Cluster Autoscaler
- Active ou désactive des nœuds dans un Node Pool selon la charge réelle
- Basé sur des seuils de CPU/mémoire
- Peut réduire la facture… si bien configuré
3. NAP (Node Auto-Provisioning)
- Provisionne dynamiquement des VMs hors des Node Pools
- Piloté automatiquement en fonction du besoin réel
- Plus granulaire, mais encore en Preview (et avec limitations)
Le cas particulier de NAP
Le Node Auto-Provisioning (NAP), inspiré de Karpenter chez AWS, vise une approche “juste ce qu’il faut”.
🧠 Idée :
Pourquoi garder des VM tournant à vide si je peux les créer à la volée, pile au moment où mes pods les réclament ?
🔍 Fonctionnement :
- Le scheduler observe la demande
- Si aucun nœud existant ne peut héberger le pod, il crée une VM dédiée avec les specs parfaites
- Quand plus rien ne tourne dessus, il la détruit
🚨 Limitations actuelles (car toujours en Preview) :
- Incompatible avec le Cluster Autoscaler
- Pas de support pour :
- Windows Node Pools
- Disk Encryption Sets
- Start/Stop des clusters (surfacturation possible)
- Zones Availability (certaines régions uniquement)
👉 À surveiller, mais à ne pas déployer en prod critique pour l’instant.
Comparatif des approches
| Critère | Manual Scale | Cluster Autoscaler | NAP / Karpenter |
|---|---|---|---|
| Complexité | Faible ✅ | Moyenne ✅ | Élevée ❌ |
| Visibilité sur les coûts | Excellente ✅ | Moyenne ❌ | Optimisée ✅ |
| Maturité | Stable ✅ | Stable ✅ | En développement ❌ |
En pratique => Ce que je recommande souvent
- System Node Pools : ne bougent presque jamais.
- Gère-les avec du
Manual Scalebien dimensionné.
- Gère-les avec du
- User Node Pools : c’est là que vit ton applicatif.
- 👉 Active le
Cluster Autoscaler, mais surveille les métriques de saturation. - Si tu touches trop souvent le “max nodes”, il est temps de revoir ta config
- 👉 Active le
- 🧪 NAP : à tester en environnement de hors prod
- 👉 Il peut t’aider à explorer une scalabilité ultra fine pour des workloads batch ou événementiels
Résilience ≠ haute dispo par défaut
AKS est solide, mais il ne garantit rien au-delà de la région.
La vraie résilience, c’est :
- De la redondance (multi-AZ, multi-region…)
- Du pilotage (monitoring, alerting)
- De la discipline (infra as code, tests de bascule, documentation claire)
Et comme toujours dans le cloud :
| ⚖️ Ce que tu gagnes en scalabilité, tu dois le payer en observabilité |
Résilience Applicative
« Un cluster peut tomber, un pod peut crasher, une dépendance peut répondre trop lentement…
Mais ton appli doit tenir. La vraie résilience commence dans le deployment.yaml. »
Déclarer les besoins de l’application
Dès la conception, la résilience passe par des manifeste Kubernetes bien pensés.
Chaque workload devrait clairement déclarer :
- Des requests pour réserver les ressources minimales nécessaires (CPU, mémoire).
- Des limits pour éviter la consommation abusive et assurer une équité entre pods.
- Des Tolerations / Node Affinity pour imposer des contraintes de scheduling précises.
Et le classique :
resources:
requests:
cpu: "0.5"
memory: "2Gi"
limits:
cpu: "4"
memory: "16Gi"
Sans ces informations :
- Le pod peut être planifié n’importe où, y compris sur des nœuds système.
- Il peut monopoliser les ressources, provoquant du throttle sur les autres workloads.
- Le recyclage ne se déclenche jamais, même si le pod déraille.
Et si un développeur définit arbitrairement des limites à 4 CPU / 16Gi alors qu’il consomme 10%, tu sur-provisionnes ton cluster pour rien.
Résultat : tu paies pour le silence.
Horizontal Pod Autoscaler (HPA)
HPA est un contrôleur natif Kubernetes qui ajuste automatiquement le nombre de pods selon :
- L’utilisation CPU
- L’utilisation mémoire (si le Metric Server est bien configuré)
- Ou des Custom Metrics (via Prometheus Adapter, par exemple)
Exemple :
spec:
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
SCALER SUR ÉVÉNEMENT
“Ton backend explose à 20 000 messages en attente ?
KEDA te balance des pods. Sans broncher.”
KEDA ( Kubernetes Event-Driven Autoscaling )
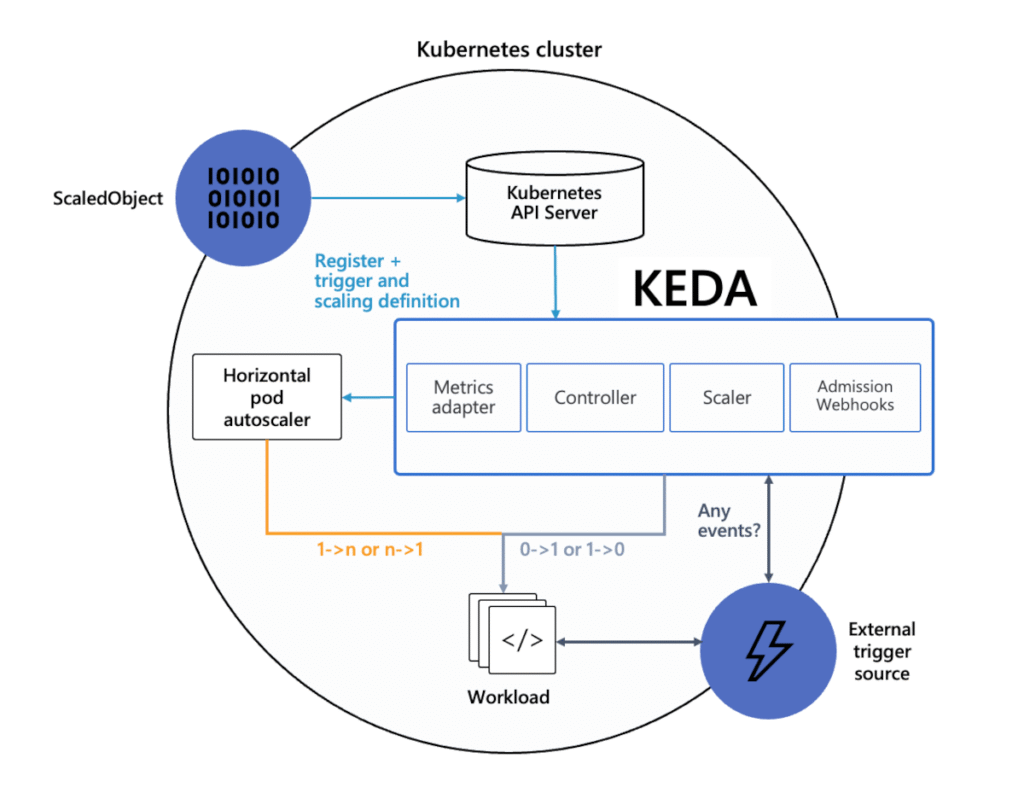
KEDA permet de déclencher un scaling applicatif non pas selon des métriques CPU classiques, mais sur des événements concrets.
Un backlog Kafka qui grossit ? Une table SQL qui déborde ? KEDA observe, réagit… et scale.
Parce que le vrai pic de charge ne vient pas toujours du CPU/RAM
Exemple : Apache Kafka
Tu as une app de traitement en temps réel, branchée sur une file Apache Kafka.
Pas de surcharge tant que le flux reste fluide.
Mais dès que les messages s’accumulent dans un topic ?
➡️ KEDA capte l’augmentation du lag Kafka
➡️ Et lance automatiquement des pods supplémentaires pour accélérer le traitement.
les patterns de résilience… sans les coder
La Résilience, intégrée by design ( Dapr )
Dapr (Distributed Application Runtime) est un projet open source initié par Microsoft, adopté largement dans la communauté cloud-native.

Son objectif est simple mais ambitieux :
➡️ Simplifier le développement d’applications résilientes, en externalisant les mécanismes complexes hors du code métier.
Dapr agit comme une couche d’abstraction portable, disponible dans n’importe quel langage, qui permet aux développeurs de se concentrer sur la logique fonctionnelle — tout en bénéficiant de patrons de résilience éprouvés.
Les Patterns Cloud-Native intégrés dans Dapr
Dapr embarque nativement plusieurs mécanismes clés de résilience :
| Pattern | Rôle |
|---|---|
| ⏱️ Timeouts | Éviter qu’une requête n’attende indéfiniment une réponse. |
| 🔁 Retry / Backoff | Réessayer automatiquement les appels externes avec une logique progressive. |
| 🚧 Circuit Breaker | Couper temporairement les appels vers un service en échec pour préserver l’ensemble du système. |
| 💓 Health Monitoring | Vérifier l’état métier d’un service via des endpoints applicatifs. |
Ces comportements peuvent être définis par configuration (policies), sans être codés dans l’application.
Exemple : un microservice d’envoi d’e-mails
Ton service notifications-api appelle un provider SMTP externe.
➡️ Avec Dapr, tu configures :
- Timeout à 3 secondes
- 3 retries maximum
- Circuit breaker si 5 erreurs consécutives
- Et un endpoint
/healthz/emailpour tester la connectivité SMTP
Résultat : si le provider rame ou tombe, ton service ne sature pas, évite les boucles infinies et peut rediriger intelligemment vers un fallback.
Déploiement sur AKS
- Dapr s’installe comme sidecar dans ton Pod Kubernetes.
- Il est invisible pour l’infra, mais redoutablement efficace côté applicatif.
- Tu peux l’installer cluster-wide via Helm ou Operator
✅ Il devient un agent de résilience as a service, au plus près de tes workloads.
LE SERVICE MESH QUI BLINDE TES COMMUNICATIONS
La résilience au cœur du réseau ( ISTIO)
Istio est une solution de Service Mesh open source, conçue pour sécuriser, contrôler et observer les communications entre tes microservices, sans modifier le code des applications
Déployé en tant que proxy sidecar (Envoy) injecté dans chaque Pod, Istio intercepte et gère tout le trafic est-ouest (interne au cluster), avec une finesse redoutable
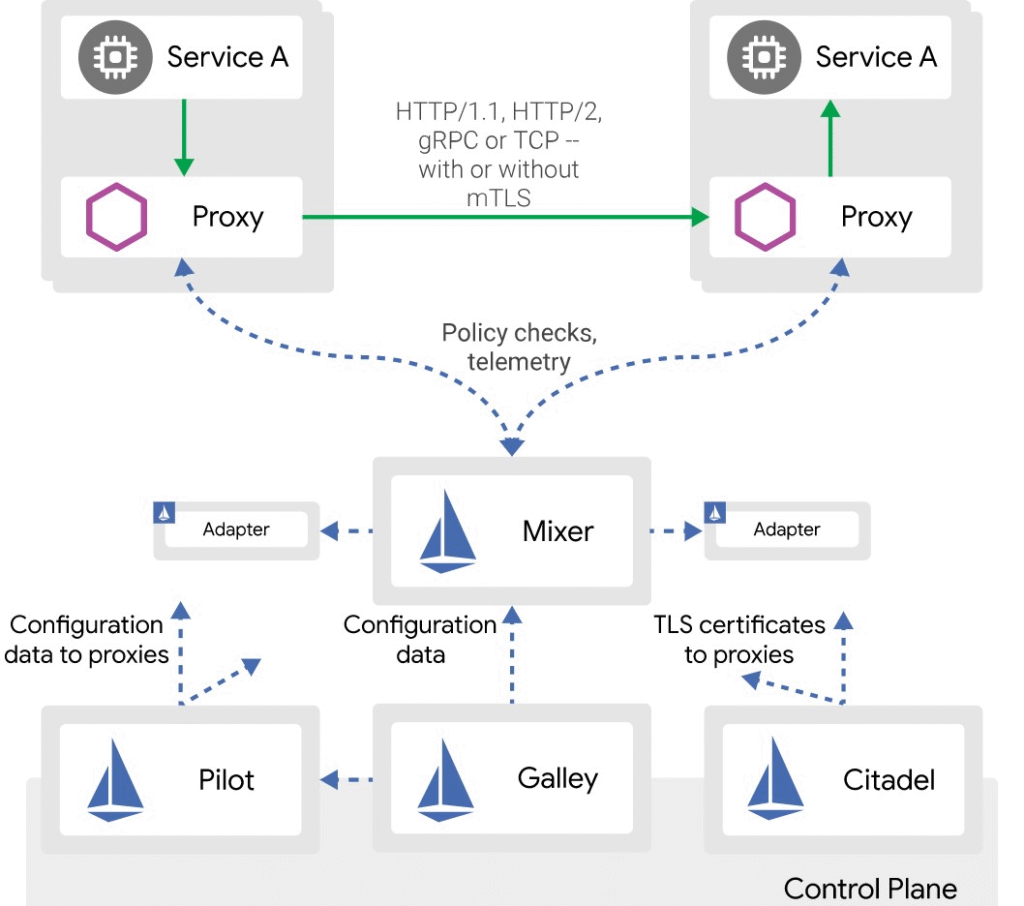
Pourquoi Istio renforce ta résilience ?
En centralisant la gestion des flux réseau, Istio permet d’implémenter facilement des stratégies avancées de tolérance aux pannes, sans intervention des développeurs.
Voici ce qu’il peut faire pour toi :
| Fonction | Description |
|---|---|
| 🔁 Retry / Timeout | Redéclenche automatiquement des requêtes en cas d’échec transitoire. |
| 🚧 Circuit Breaker | Isole un service en panne pour éviter d’aggraver la situation. |
| ➕ Load Balancing | Répartit le trafic entre plusieurs instances en fonction de règles avancées. |
| 🌐 Traffic Shifting | Dirige un pourcentage du trafic vers une nouvelle version (canary, A/B). |
| 📈 Health-Based Routing | Ne dirige le trafic qu’aux instances saines. |
Exemple :
un microservice critique qui appelle un service de facturation
Tu veux éviter que toute la chaîne plante si billing-api ne répond plus ?
Avec Istio, tu peux définir via un simple manifeste :
- 3 tentatives de retry avec timeout à 2 secondes
- Circuit breaker après 5 erreurs sur une fenêtre de 30s
- Fallback automatique vers une version de secours (shadow service)
- Redirection du trafic vers une version canary à 10%
Et tout ça, sans toucher au code du microservice.
Déploiement AKS :
- Istio est supporté sur AKS, même si non natif.
- Installation via
istioctlou Helm. - Intégration possible avec Kiali (visualisation du maillage), Jaeger (tracing), Prometheus/Grafana (metrics)
Tu gagnes une vision complète du trafic + contrôle dynamique sans modifier une seule ligne d’application
4. CONCLUSION
Un upgrade bien préparé, c’est déjà la moitié de la bataille.
Anticiper les breaking changes, choisir la bonne stratégie (canary, blue/green…), et dimensionner correctement ton cluster, c’est ce qui fait la différence entre une mise à jour fluide… et une nuit blanche.
Mais attention : sans sauvegarde, tout ça reste fragile.
👉 Tu peux avoir le meilleur design du monde, si un volume disparaît ou si ton etcd est corrompu, tu n’as plus aucun filet.
PROCHAIN ARTICLE
👉 La Partie 2 sera dédiée à la sauvegarde et la restauration dans AKS
On verra :
- Comment protéger ton infrastructure via l’IaC.
- Comment capturer l’état du cluster (etcd, RBAC, secrets, objets Kubernetes).
- Comment sécuriser les volumes persistants (PVC, snapshots, Velero, AKS Native Backup).
- Et surtout, comment tester tes plans de reprise pour éviter la panique en prod.